Menemukan Subdomains¶
Untuk menentukan cakupan dan menguji titik akhir API, pertama-tama kita harus memahami struktur domain yang digunakan aplikasi web. Di dunia saat ini, sangat jarang satu domain digunakan untuk melayani aplikasi web secara keseluruhan. Sering kali, aplikasi web akan dibagi menjadi minimal domain klien dan server, ditambah "https://www" yang umum digunakan, alih-alih hanya "https://". Kemampuan untuk menemukan dan merekam subdomain yang mendukung aplikasi web secara berulang merupakan teknik pengintaian pertama yang berguna terhadap aplikasi web tersebut.
Beberapa Aplikasi per Domain¶
Mari kita asumsikan kita sedang mencoba memetakan aplikasi web MegaBank agar dapat melakukan uji penetrasi kotak hitam yang disponsori oleh bank tersebut dengan lebih baik. Kita tahu bahwa MegaBank memiliki aplikasi yang dapat digunakan pengguna untuk masuk dan mengakses rekening bank mereka. Aplikasi ini terletak di https://www.mega-bank.com. Kami sangat ingin tahu apakah MegaBank memiliki server lain yang dapat diakses internet yang terhubung ke nama domain mega-bank.com. Kita tahu MegaBank memiliki program bug bounty, dan cakupan program tersebut mencakup domain utama mega-bank.com secara cukup komprehensif. Akibatnya, setiap kerentanan yang mudah ditemukan di mega-bank.com telah diperbaiki atau dilaporkan. Jika ada kerentanan baru yang muncul, kami akan bekerja keras untuk menemukannya sebelum para pemburu bug bounty menemukan.
Oleh karena itu, kami ingin mencari beberapa target yang lebih mudah yang masih memungkinkan kami untuk menyerang MegaBank di titik lemahnya. Ini adalah uji coba yang murni etis dan disponsori perusahaan, tetapi bukan berarti kami tidak bisa bersenang-senang. Hal pertama yang harus kami lakukan adalah melakukan pengintaian dan mengisi peta aplikasi web kami dengan daftar subdomain yang terhubung dengan mega-bank.com (lihat Gambar 4-1). Karena www mengarah ke aplikasi web publik itu sendiri, kami mungkin tidak tertarik dengan hal itu. Namun, sebagian besar perusahaan konsumen besar sebenarnya menghosting berbagai subdomain yang terhubung ke domain utama mereka. Subdomain ini digunakan untuk menghosting berbagai layanan mulai dari email, aplikasi admin, server berkas, dan lainnya.
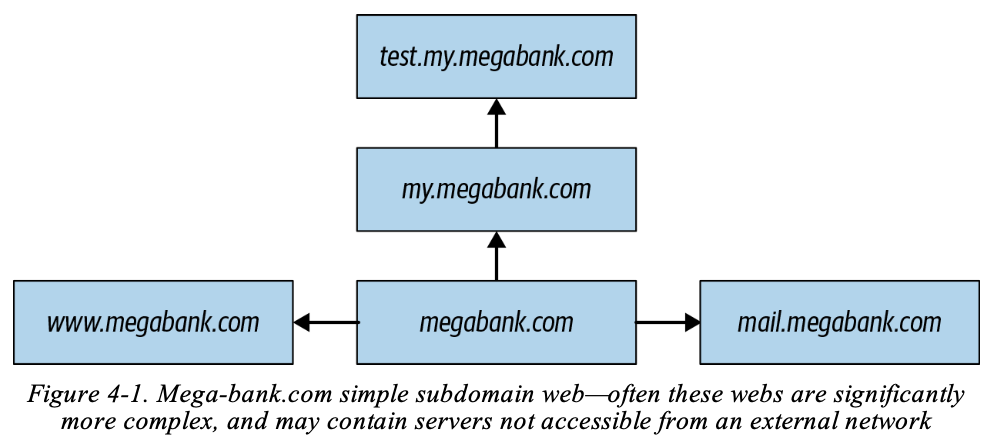
Ada banyak cara untuk menemukan data ini, dan seringkali Anda harus mencoba beberapa cara untuk mendapatkan hasil yang Anda inginkan. Kita akan mulai dengan metode yang paling sederhana dan terus meningkat.
Alat Analisis Jaringan Bawaan Browser¶
Awalnya, kita dapat mengumpulkan beberapa data bermanfaat hanya dengan menelusuri fungsi yang terlihat di MegaBank dan melihat permintaan API apa yang dibuat di latar belakang. Hal ini seringkali memberikan kita beberapa titik akhir yang mudah diakses. Untuk melihat permintaan ini saat dibuat, kita dapat menggunakan alat jaringan peramban web kita sendiri, atau alat yang lebih canggih seperti Burp, PortSwigger, atau ZAP.
Gambar 4-2 menunjukkan contoh alat pengembang peramban Wikipedia, yang dapat digunakan untuk melihat, mengubah, mengirim ulang, dan merekam permintaan jaringan. Alat analisis jaringan yang tersedia gratis seperti ini jauh lebih canggih daripada banyak alat jaringan berbayar dari 10 tahun yang lalu. Karena buku ini ditulis tanpa menyertakan alat khusus, untuk saat ini kita hanya akan mengandalkan peramban.
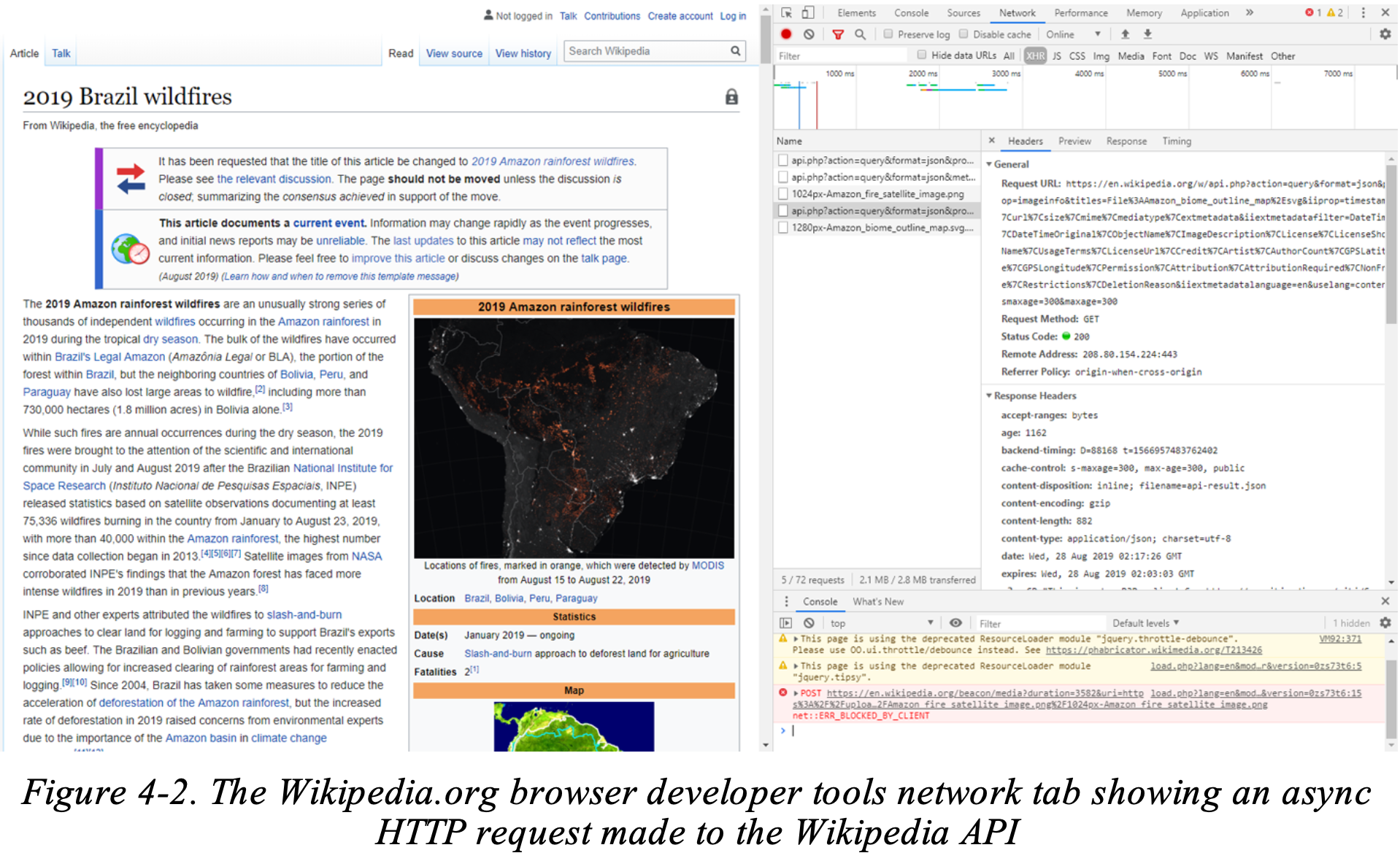
Selama Anda menggunakan salah satu dari tiga peramban utama (Chrome, Firefox, atau Edge), Anda akan merasakan bahwa alat yang disertakan untuk pengembang sangatlah canggih. Bahkan, alat pengembang peramban telah berkembang pesat sehingga Anda dapat dengan mudah menjadi peretas yang mahir tanpa harus membeli alat pihak ketiga apa pun. Peramban modern menyediakan alat untuk analisis jaringan, analisis kode, analisis runtime JavaScript dengan breakpoint dan referensi berkas, pengukuran kinerja yang akurat (yang juga dapat digunakan sebagai alat peretasan dalam serangan side-channel), serta alat untuk melakukan audit keamanan dan kompatibilitas kecil.
Untuk menganalisis lalu lintas jaringan yang melalui peramban Anda, lakukan hal berikut (di Chrome):
Klik tiga titik di kanan atas bilah navigasi untuk membuka menu Pengaturan.
Di bawah "Alat lainnya", klik "Alat pengembang".
Di bagian atas menu ini, klik tab "Jaringan". Jika tidak terlihat, perluas alat pengembang secara horizontal hingga terlihat.
Sekarang, cobalah menavigasi halaman-halaman di situs web mana pun saat tab Jaringan terbuka. Perhatikan bahwa permintaan HTTP baru akan muncul bersama sejumlah permintaan lainnya (lihat Gambar 4-3).
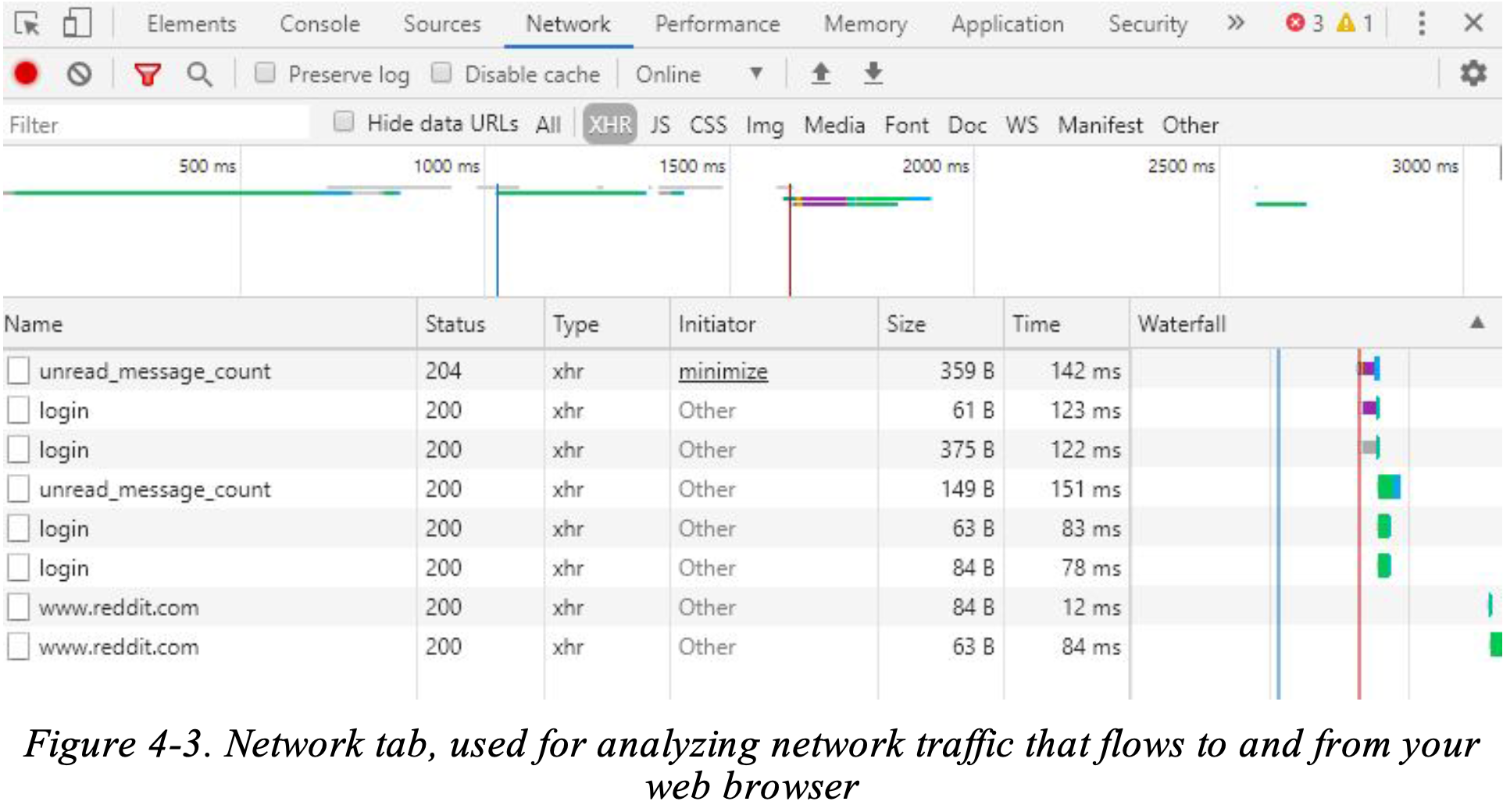
Anda dapat menggunakan tab Jaringan di peramban untuk melihat semua lalu lintas jaringan yang ditangani peramban. Untuk situs yang lebih besar, penyaringannya bisa cukup rumit.
Seringkali hasil yang paling menarik datang dari tab XHR, di bawah tab Jaringan, yang akan menampilkan semua permintaan HTTP POST, GET, PUT, DELETE, dan permintaan lainnya yang dibuat terhadap server, dan memfilter font, gambar, video, dan berkas dependensi. Anda dapat mengeklik setiap permintaan individual di panel sebelah kiri untuk melihat detail selengkapnya.
Mengklik salah satu permintaan ini akan menampilkan versi mentah dan terformat dari permintaan tersebut, termasuk header dan isi permintaan. Di tab Pratinjau yang muncul ketika permintaan dipilih, Anda akan dapat melihat versi terformat cantik dari hasil setiap permintaan API.
Tab Respons di bawah XHR akan menampilkan muatan respons mentah, dan tab Pengaturan Waktu akan menampilkan metrik yang sangat spesifik tentang waktu antre, pengunduhan, dan waktu tunggu yang terkait dengan suatu permintaan. Metrik kinerja ini sebenarnya sangat penting karena dapat digunakan untuk menemukan serangan saluran samping (serangan yang mengandalkan metrik sekunder selain respons untuk mengukur kode apa yang berjalan di server; misalnya, waktu muat antara dua skrip di server yang keduanya dipanggil melalui titik akhir yang sama).
Sekarang Anda seharusnya sudah cukup familiar dengan tab Jaringan di peramban untuk mulai menjelajahi dan memanfaatkannya untuk pengintaian. Perkakasnya memang menakutkan, tetapi sebenarnya tidak terlalu sulit untuk dipelajari.
Saat Anda menavigasi situs web mana pun, Anda dapat memeriksa permintaan → tajuk → umum → URL permintaan untuk melihat domain mana permintaan dikirim atau respons dikirim. Seringkali ini adalah semua yang Anda butuhkan untuk menemukan server afiliasi dari situs web utama.
Memanfaatkan Catatan Publik¶
Saat ini, jumlah informasi publik yang tersimpan di web begitu besar sehingga kebocoran data yang tidak disengaja dapat lolos tanpa pemberitahuan selama bertahun-tahun. Peretas yang handal dapat memanfaatkan fakta ini dan menemukan banyak informasi menarik yang dapat mengarah pada serangan mudah di kemudian hari.
Beberapa data yang saya temukan di web saat melakukan uji penetrasi di masa lalu meliputi:
Salinan cache repositori GitHub yang secara tidak sengaja diubah menjadi publik sebelum diubah menjadi privat lagi Kunci SSH
Berbagai kunci untuk layanan seperti Amazon AWS atau Stripe yang terekspos secara berkala dan kemudian dihapus dari aplikasi web yang dapat diakses publik
Daftar DNS dan URL yang tidak ditujukan untuk khalayak publik
Halaman yang merinci produk yang belum dirilis yang tidak dimaksudkan untuk dipublikasikan
Catatan keuangan yang dihosting di web tetapi tidak dimaksudkan untuk dijelajahi oleh mesin pencari
Alamat email, nomor telepon, dan nama pengguna
Informasi ini dapat ditemukan di banyak tempat, seperti:
Mesin pencari
Postingan media sosial
Aplikasi pengarsipan, seperti archive.org
Pencarian gambar dan reverse image searches
Saat mencoba menemukan subdomain, catatan publik juga dapat menjadi sumber informasi yang baik karena subdomain mungkin tidak mudah ditemukan melalui kamus, tetapi mungkin telah diindeks di salah satu layanan yang tercantum sebelumnya.
Cache Mesin Pencari¶
Google adalah mesin pencari yang paling umum digunakan di dunia, dan sering dianggap telah mengindeks lebih banyak data daripada mesin pencari lainnya. Pencarian Google sendiri tidak akan berguna untuk pencarian manual karena banyaknya data yang harus disaring untuk menemukan sesuatu yang berharga. Hal ini diperparah oleh fakta bahwa Google telah menindak permintaan otomatis dan menolak permintaan yang tidak meniru secara akurat permintaan peramban web yang sebenarnya.
Untungnya, Google menawarkan operator pencarian khusus untuk pencari
yang handal yang memungkinkan Anda meningkatkan spesifisitas
permintaan pencarian Anda. Kita dapat menggunakan operator site:<my-site> untuk meminta
Google agar hanya melakukan pencarian terhadap domain tertentu:
site:mega-bank.com log in
Melakukan hal ini pada situs populer biasanya akan menampilkan halaman demi halaman konten dari domain utama, dan sangat sedikit konten dari subdomain yang menarik. Anda perlu meningkatkan fokus pencarian Anda lebih lanjut untuk mulai menemukan hal-hal menarik.
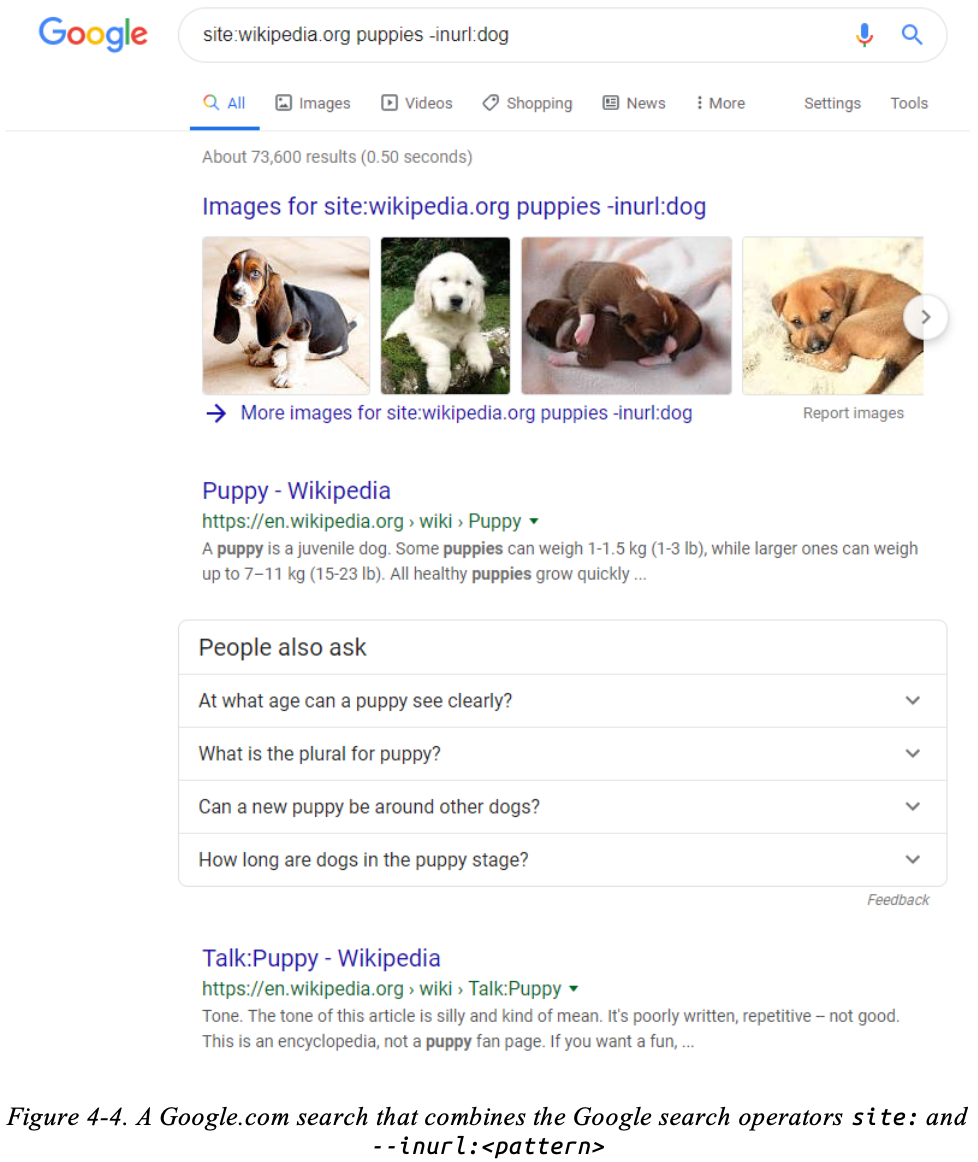
Gunakan operator minus untuk menambahkan kondisi negatif tertentu ke string kueri apa pun. Misalnya, -inurl:<pattern> akan menolak URL apa pun yang cocok dengan pola yang diberikan. Gambar 4-4 menunjukkan contoh pencarian yang menggabungkan operator pencarian Google,
site:, dan --inurl:<pattern>. Dengan menggabungkan kedua operator ini,
kita dapat meminta Google untuk hanya menampilkan halaman web wikipedia.org yang membahas tentang anak anjing, dan mengabaikan halaman yang mengandung kata "dog" di URL-nya. Teknik ini dapat digunakan untuk mengurangi jumlah hasil pencarian yang ditampilkan, dan untuk mencari subdomain tertentu sambil mengabaikan kata kunci tertentu. Menguasai operator pencarian Google dan operator di mesin pencari lain akan memungkinkan Anda menemukan informasi yang tidak mudah ditemukan.
Kita dapat menggunakan operator --inurl:<pattern> untuk menghapus hasil
untuk subdomain yang sudah kita kenal, seperti www.
Perhatikan bahwa operator ini juga akan memfilter kemunculan www dari
bagian lain URL, karena tidak menentukan subdomain melainkan
seluruh string URL. Ini berarti
https://admin.mega-bank.com/www juga akan difilter
, yang berarti mungkin ada penghapusan positif palsu:
site:mega-bank.com -inurl:www
Anda dapat mencoba ini di banyak situs, dan Anda akan menemukan subdomain yang bahkan tidak Anda duga ada. Misalnya, mari kita coba di situs berita populer Reddit:
site:reddit.com -inurl:www
Hasil pertama dari kueri ini adalah code.reddit.com — sebuah arsip kode yang digunakan dalam versi awal Reddit yang staf putuskan untuk dipublikasikan. Situs web seperti Reddit sengaja mengekspos domain-domain ini ke publik. Untuk uji pena kami terhadap MegaBank, jika kami menemukan domain tambahan yang sengaja diekspos dan tidak menarik bagi kami, kami akan memfilternya juga. Jika MegaBank memiliki versi seluler yang dihosting di bawah subdomain mobile.mega- bank.com, kami juga dapat dengan mudah memfilternya:
site:mega-bank.com -inurl:www -inurl:mobile
Saat mencoba menemukan subdomain untuk situs tertentu, Anda dapat mengulangi proses ini hingga Anda tidak menemukan hasil yang lebih relevan. Mungkin juga bermanfaat untuk mencoba teknik ini terhadap mesin pencari lain seperti Bing—semua mesin pencari besar mendukung operator yang serupa.
Catat apa pun yang menarik yang Anda temukan melalui teknik ini lalu lanjutkan ke metode pengintaian subdomain lainnya.
Arsip Tak Sengaja¶
Utilitas pengarsipan publik seperti archive.org bermanfaat karena membuat snapshot situs web secara berkala dan memungkinkan Anda mengunjungi salinan situs web dari masa lalu. Archive.org berupaya melestarikan sejarah internet, karena banyak situs yang tutup dan situs baru mengambil alih domain mereka. Karena Archive.org menyimpan snapshot historis situs web, terkadang hingga 20 tahun yang lalu, situs web ini merupakan tambang emas untuk menemukan informasi yang pernah diungkapkan (sengaja atau tidak sengaja) tetapi kemudian dihapus. Tangkapan layar tertentu pada Gambar 4-5 adalah halaman beranda Wikipedia.org yang diindeks pada tahun 2003—hampir dua dekade yang lalu!
Secara umum, mesin pencari akan mengindeks data mengenai suatu situs web, tetapi mencoba merayapi situs web tersebut secara berkala agar cache-nya tetap mutakhir. Ini berarti bahwa untuk data terkini yang relevan, Anda harus mencarinya di mesin pencari, tetapi untuk data historis yang relevan, Anda mungkin lebih baik melihat arsip situs web.
The New York Times adalah salah satu perusahaan media berbasis web terpopuler berdasarkan lalu lintas. Jika kita mencari situs web utamanya di Archive.org (https://www.nytimes.com), kita akan menemukan bahwa Archive.org telah menyimpan lebih dari 200.000 cuplikan halaman depan antara tahun 1996 dan sekarang.
Cuplikan historis sangat berharga jika kita mengetahui atau dapat menebak titik waktu ketika suatu aplikasi web mengirimkan rilis utama, atau memiliki kerentanan keamanan yang serius yang diungkapkan. Saat mencari subdomain, arsip historis sering kali mengungkapkannya melalui hyperlink yang pernah terekspos melalui HTML atau JS tetapi tidak lagi terlihat di aplikasi langsung.
Jika kita klik kanan snapshot Archive.org di peramban kita dan pilih "View source", kita dapat melakukan pencarian cepat untuk pola URL umum. Pencarian untuk file:// mungkin akan menampilkan unduhan yang sebelumnya aktif, sementara pencarian untuk https:// atau http:// akan menampilkan semua hyperlink HTTP.
Kita dapat mengotomatiskan penemuan subdomain dari arsip dengan langkah-langkah sederhana berikut:
Buka 10 arsip dari 10 tanggal terpisah dengan selingan waktu yang signifikan.
Klik kanan "Lihat sumber", " lalu tekan Ctrl-A untuk menyorot semua HTML.
Tekan Ctrl-C untuk menyalin HTML ke clipboard Anda.
Buat berkas di desktop Anda dengan nama legacy-source.html.
Tekan Ctrl-V untuk menempelkan kode sumber dari arsip ke dalam berkas tersebut.
Ulangi langkah ini untuk masing-masing dari sembilan arsip lain yang Anda buka.
Buka berkas ini di editor teks favorit Anda (VIM, Atom, VSCode, dll.).
Lakukan pencarian untuk skema URL yang paling umum: http:// https:// file:// ftp:// ftps://
Anda dapat menemukan daftar lengkap skema URL yang didukung browser dalam dokumen spesifikasi, yang digunakan di semua browser utama untuk menentukan skema mana yang harus didukung.
Sosial Snapshots¶
Setiap situs web media sosial besar saat ini menghasilkan uang dari penjualan data pengguna, yang, tergantung pada platformnya, dapat mencakup kiriman publik, kiriman pribadi, dan bahkan pesan langsung dalam beberapa kasus.
Sayangnya, perusahaan media sosial besar saat ini berupaya keras untuk meyakinkan pengguna bahwa data paling pribadi mereka aman. Hal ini sering dilakukan melalui pesan pemasaran yang menggambarkan upaya keras yang dilakukan untuk menjaga data pelanggan jauh dari jangkauan. Namun, hal ini seringkali hanya dikatakan untuk membantu menarik dan mempertahankan pengguna aktif. Sangat sedikit negara yang memiliki undang-undang dan pembuat undang-undang yang cukup modern untuk menegakkan legitimasi klaim-klaim ini. Kemungkinan besar banyak pengguna situs-situs ini tidak sepenuhnya memahami data apa yang dibagikan, dengan metode apa data tersebut dibagikan, dan untuk tujuan apa data ini dikonsumsi.
Mencari subdomain untuk uji pena yang disponsori perusahaan melalui data media sosial tidak akan dianggap tidak etis oleh kebanyakan orang. Namun, saya mohon Anda untuk mempertimbangkan pengguna akhir saat menggunakan API ini di masa mendatang untuk pengintaian yang lebih terarah.
Untuk menyederhanakannya, kita akan melihat API Twitter sebagai contoh pengintaian. Namun, perlu diingat bahwa setiap perusahaan media sosial besar menawarkan rangkaian API yang serupa yang biasanya mengikuti struktur API yang serupa. Konsep yang diperlukan untuk melakukan kueri dan pencarian melalui data tweet dari API Twitter dapat diterapkan ke jaringan media sosial besar lainnya.
TWITTER API¶
Twitter memiliki sejumlah penawaran untuk mencari dan memfilter data mereka (lihat Gambar 4-6). Penawaran ini berbeda dalam cakupan, rangkaian fitur, dan rangkaian data. Ini berarti semakin banyak data yang ingin Anda akses dan semakin banyak cara yang Anda inginkan untuk meminta dan memfilter data tersebut, semakin banyak pula biaya yang harus Anda bayar. Dalam beberapa kasus, pencarian bahkan dapat dilakukan terhadap server Twitter alih-alih secara lokal. Perlu diingat bahwa melakukan hal ini untuk tujuan jahat kemungkinan melanggar Ketentuan Layanan Twitter, sehingga penggunaan ini harus dibatasi hanya untuk white hat.
Di tingkat paling bawah, Twitter menawarkan "API pencarian" uji coba yang memungkinkan Anda menyaring tweet selama 30 hari dengan syarat Anda meminta tidak lebih dari 100 tweet per kueri, dan kueri tidak lebih dari 30 kali per menit. Dengan API tingkat gratis, total kueri bulanan Anda juga dibatasi hingga 250. Diperlukan sekitar 10 menit kueri untuk mendapatkan kumpulan data bulanan maksimum yang ditawarkan pada tingkat ini. Ini berarti Anda hanya dapat menganalisis 25.000 tweet tanpa membayar untuk tingkat keanggotaan yang lebih canggih.
Keterbatasan ini dapat membuat alat pengkodean untuk menganalisis API agak sulit. Jika Anda memerlukan Twitter untuk pengintaian dalam proyek yang disponsori pekerjaan, Anda mungkin ingin mempertimbangkan untuk meningkatkan atau mencari sumber data lain.
Kita dapat menggunakan API ini untuk membuat JSON yang berisi tautan ke * .mega-bank.com untuk melanjutkan rekonsiliasi subdomain kita. Untuk memulai kueri terhadap API pencarian Twitter, Anda memerlukan hal-hal berikut:
Akun pengembang terdaftar
Aplikasi terdaftar
Token pembawa untuk disertakan dalam permintaan Anda guna mengautentikasi diri Anda
Menanyakan API ini cukup mudah, meskipun dokumentasinya tersebar dan terkadang sulit dipahami karena kurangnya contoh:
curl --request POST \
--url
https://api.twitter.com/1.1/tweets/search/30day/Prod.json
\
--header 'authorization: Bearer <MY
_
TOKEN>' \
--header 'content-type: application/json' \
--data '{
"maxResults": "100"
,
"keyword
Secara default, API ini melakukan pencarian fuzzy terhadap kata kunci. Untuk kecocokan persis, Anda harus memastikan bahwa string yang dikirimkan diapit tanda kutip ganda. Tanda kutip ganda dapat dikirimkan melalui JSON yang valid dalam format: "kata kunci": ""mega-bank.com"".
Merekam hasil API ini dan mencari tautan dapat mengarah pada penemuan subdomain yang sebelumnya tidak diketahui. Subdomain ini biasanya berasal dari kampanye pemasaran, pelacak iklan, dan bahkan acara perekrutan yang terhubung ke server yang berbeda dari aplikasi utama.
Sebagai contoh nyata, cobalah membuat kueri yang akan meminta tweet tentang Microsoft. Setelah menyaring cukup banyak tweet, Anda akan melihat bahwa Microsoft memiliki sejumlah subdomain yang secara aktif dipromosikan di Twitter, termasuk:
careers.microsoft.com (situs lowongan kerja)
office.microsoft.com (situs web Microsoft Office)
powerbi.microsoft.com (situs web produk PowerBI)
support.microsoft.com (dukungan pelanggan Microsoft)
Perlu diketahui bahwa jika sebuah tweet menjadi cukup populer, mesin pencari utama akan mulai mengindeksnya. Jadi, menganalisis API Twitter akan lebih relevan jika Anda mencari tweet yang kurang populer. Tweet viral yang sangat populer akan diindeks oleh mesin pencari karena banyaknya tautan masuk. Ini berarti terkadang lebih efektif untuk sekadar mencari di mesin pencari menggunakan operator yang tepat, seperti yang telah dibahas sebelumnya di bab ini.
Jika hasil API ini tidak mencukupi untuk proyek pencarian Anda, Twitter juga menawarkan dua API lain: streaming dan firehose.
API streaming Twitter menyediakan streaming langsung tweet terkini untuk dianalisis secara real-time; namun, API ini hanya menawarkan persentase yang sangat kecil dari tweet langsung yang sebenarnya karena volumenya terlalu besar untuk diproses dan dikirim ke pengembang secara real-time. Ini berarti Anda bisa kehilangan lebih dari 99% tweet kapan saja. Jika aplikasi yang Anda teliti sedang tren atau sangat populer, API ini bisa bermanfaat. Jika Anda melakukan pengintaian untuk perusahaan rintisan, API ini tidak akan terlalu berguna bagi Anda.
API firehose Twitter beroperasi serupa dengan API streaming, tetapi menjamin pengiriman 100% tweet yang sesuai dengan kriteria yang Anda berikan. Ini biasanya jauh lebih berharga daripada API streaming untuk pengintaian, karena kami lebih mengutamakan relevansi daripada kuantitas dalam kebanyakan situasi.
Kesimpulannya, saat menggunakan Twitter sebagai alat pengintaian, ikuti aturan berikut:
Untuk sebagian besar aplikasi web, meminta API pencarian akan memberi Anda data yang paling relevan untuk pengintaian.
Aplikasi berskala besar, atau aplikasi yang sedang tren, mungkin memiliki informasi bermanfaat yang dapat ditemukan di API firehose atau streaming.
Jika informasi historis dapat diterima untuk situasi Anda, pertimbangkan untuk mengunduh data historis yang besar dari tweet dan meminta data tersebut secara lokal sebagai gantinya.
Ingat, hampir semua situs media sosial besar menawarkan API data yang dapat digunakan untuk pengintaian atau bentuk analisis lainnya. Jika salah satu tidak memberikan hasil yang Anda cari, mungkin ada yang lain.
Zone Transfer Attacks¶
Menelusuri aplikasi web publik dan menganalisis permintaan jaringan hanya akan membantu Anda sampai di sini. Kami juga ingin menemukan subdomain yang terhubung ke MegaBank yang tidak terhubung ke aplikasi web publik tersebut dengan cara apa pun.
Serangan transfer zona (zone transfer attack) adalah semacam trik pengintaian yang berfungsi melawan server Sistem Nama Domain (DNS) yang tidak dikonfigurasi dengan benar. Ini sebenarnya bukan "peretasan", meskipun namanya menunjukkan bahwa memang demikian. Sebaliknya, ini hanyalah teknik pengumpulan informasi yang mudah digunakan, dan dapat memberi kita informasi berharga jika berhasil. Pada intinya, serangan transfer zona DNS adalah permintaan yang diformat khusus atas nama individu yang dirancang agar terlihat seperti permintaan transfer zona DNS yang valid dari server DNS yang valid.
Server DNS bertanggung jawab untuk menerjemahkan nama domain yang dapat dibaca manusia (misalnya, https://mega-bank.com) menjadi alamat IP yang dapat dibaca mesin (misalnya, 195.250.100.195), yang bersifat hierarkis dan disimpan menggunakan pola umum sehingga dapat dengan mudah diminta dan diakses. Server DNS berharga karena memungkinkan alamat IP server untuk berubah, tanpa harus memperbarui pengguna aplikasi di server tersebut. Dengan kata lain, pengguna dapat terus mengunjungi https://www.mega-bank.com tanpa perlu khawatir server mana yang akan menerima permintaan tersebut.
Sistem DNS sangat bergantung pada kemampuannya untuk mensinkronkan pembaruan rekaman DNS dengan server DNS lainnya. Transfer zona DNS adalah cara standar bagi server DNS untuk berbagi rekaman DNS. Rekaman dibagikan dalam format berbasis teks yang dikenal sebagai berkas zona.
Berkas zona sering kali berisi data konfigurasi DNS yang tidak dimaksudkan untuk mudah diakses. Akibatnya, server master DNS yang dikonfigurasi dengan benar seharusnya hanya dapat menyelesaikan permintaan transfer zona yang diminta oleh server slave DNS resmi lainnya. Jika server DNS tidak dikonfigurasi dengan benar untuk hanya menyelesaikan permintaan untuk server DNS lain yang didefinisikan secara khusus, server tersebut akan rentan terhadap pelaku kejahatan
Singkatnya, jika kita ingin mencoba serangan transfer zona terhadap MegaBank, kita perlu berpura-pura menjadi server DNS dan meminta berkas zona DNS seolah-olah kita membutuhkannya untuk memperbarui data kita sendiri. Pertama-tama, kita perlu menemukan server DNS yang terkait dengan https://www.mega-bank.com. Kita dapat melakukannya dengan sangat mudah di sistem berbasis Unix apa pun dari terminal:
host -t mega-bank.com
Perintah "host" mengacu pada utilitas pencarian DNS yang dapat Anda temukan di sebagian besar distro Linux maupun di versi terbaru macOS. Tanda -t menentukan bahwa kita ingin meminta nameserver yang bertanggung jawab untuk menyelesaikan mega-bank.com.
Keluaran dari perintah ini akan terlihat seperti ini:
mega-bank.com name server ns1.bankhost.com
mega-bank.com name server ns2.bankhost.com
String yang kami cari dari hasil ini adalah
ns1.bankhost.com dan ns2.bankhost.com. String ini merujuk pada
dua nameserver yang menyelesaikan mega-bank.com.
Mencoba membuat permintaan transfer zona dengan host sangatlah
mudah, dan hanya membutuhkan satu baris:
host -l mega-bank.com ns1.bankhost.com
Di sini, flag -l menunjukkan bahwa kita ingin mendapatkan berkas transfer zona untuk mega-bank.com dari ns1.bankhost.com untuk memperbarui records kita.
Jika permintaan berhasil, yang menunjukkan server DNS tidak diamankan dengan benar, Anda akan melihat hasil seperti ini:
Using domain server:
Name: ns1.bankhost.com
Address: 195.11.100.25
Aliases:
mega-bank.com has address 195.250.100.195
mega-bank.com name server ns1.bankhost.com
mega-bank.com name server ns2.bankhost.com
mail.mega-bank.com has address 82.31.105.140
admin.mega-bank.com has address 32.45.105.144
internal.mega-bank.com has address 25.44.105.144
Dari hasil ini, Anda sekarang memiliki daftar aplikasi web lain yang dihosting di domain mega-bank.com, beserta alamat IP publiknya!
Anda bahkan dapat mencoba menavigasi ke subdomain atau alamat IP tersebut untuk melihat apa yang berhasil diatasi. Dengan sedikit keberuntungan, Anda telah memperluas jangkauan serangan Anda!
Sayangnya, serangan transfer zona DNS tidak selalu berjalan sesuai rencana seperti pada contoh sebelumnya. Server yang dikonfigurasi dengan benar akan memberikan output yang berbeda ketika Anda meminta transfer zona:
Using domain server:
Name: ns1.secure-bank.com
Address: 141.122.34.45
Aliases:
: Transfer Failed.
Serangan transfer zona mudah dihentikan, dan Anda akan menemukan bahwa banyak aplikasi dikonfigurasi dengan benar untuk menolak upaya ini. Namun, karena mencoba serangan transfer zona hanya membutuhkan beberapa baris Bash, hampir selalu patut dicoba. Jika berhasil, Anda akan mendapatkan sejumlah subdomain menarik yang mungkin tidak Anda temukan sebelumnya.
Brute Forcing Subdomains¶
Sebagai langkah terakhir dalam menemukan subdomain, taktik brute force dapat digunakan. Taktik ini efektif terhadap aplikasi web dengan sedikit mekanisme keamanan, tetapi terhadap aplikasi web yang lebih mapan dan aman, kita akan menemukan bahwa brute force kita harus terstruktur dengan sangat cerdas.
Subdomain yang dipaksakan secara brute force harus menjadi pilihan terakhir kita karena upaya brute force mudah dicatat dan seringkali sangat memakan waktu karena keterbatasan kecepatan, regex, dan mekanisme keamanan sederhana lainnya yang dikembangkan untuk mencegah jenis pengintaian semacam itu.
Peringatan
Serangan brute force sangat mudah dideteksi dan dapat mengakibatkan alamat IP Anda dicatat atau diblokir oleh server atau adminnya.
Brute force berarti menguji setiap kemungkinan kombinasi subdomain hingga menemukan kecocokan. Dengan subdomain, bisa ada banyak kemungkinan kecocokan, jadi berhenti pada kecocokan pertama mungkin tidak cukup.
Pertama, mari kita pertimbangkan bahwa tidak seperti brute force lokal, brute force subdomain terhadap domain target memerlukan konektivitas jaringan. Karena kita harus melakukan brute force ini dari jarak jauh, upaya kita akan semakin lambat karena latensi jaringan. Secara umum, Anda dapat mengharapkan latensi antara 50 dan 250 ms per permintaan jaringan.
Ini berarti kita harus membuat permintaan kita asinkron, dan melaksanakannya secepat mungkin daripada menunggu respons sebelumnya. Melakukan hal ini akan secara drastis mengurangi waktu yang dibutuhkan untuk menyelesaikan brute force kita.
Umpan balik yang diperlukan untuk mendeteksi subdomain aktif
cukup sederhana. Algoritme brute force kami menghasilkan
subdomain, dan kami mengirimkan permintaan ke <subdomain-
guess>.mega-bank.com. Jika kami menerima respons, kami menandainya sebagai
subdomain aktif. Jika tidak, kami menandainya sebagai
subdomain yang tidak digunakan.
Karena buku yang Anda baca berjudul Web Application
Security, bahasa pemrograman terpenting yang harus kita pahami
dalam konteks ini adalah JavaScript. JavaScript bukan hanya
satu-satunya bahasa pemrograman yang saat ini tersedia untuk skrip sisi klien
di peramban web, tetapi juga bahasa sisi server
backend yang sangat canggih berkat Node.js dan komunitas sumber terbuka.
Mari kita buat algoritma brute force dalam dua langkah menggunakan JavaScript. Skrip kita akan melakukan hal berikut:
Buat daftar subdomain potensial.
Jalankan daftar subdomain tersebut, lakukan ping setiap kali untuk mendeteksi apakah suatu subdomain aktif.
Catat subdomain yang aktif dan jangan lakukan apa pun terhadap subdomain yang tidak digunakan.
Kita dapat membuat subdomain menggunakan perintah berikut:
/*
* A simple function for brute forcing a list of subdomains
* given a maximum length of each subdomain.
*/
const generateSubdomains = function(length) {
/*
*
* A list of characters from which to generate subdomains.
* This can be altered to include less common characters
* like '-'.
*
* Chinese, Arabic, and Latin characters are also
* supported by some browsers.
*/
const charset = 'abcdefghijklmnopqrstuvwxyz' .split('');
let subdomains = charset;
let subdomain;
let letter;
let temp;
/*
* Time Complexity: o(n*m)
* n = length of string
* m = number of valid characters
*/
for (let i = 1; i < length; i++) {
temp = [];
for (let k = 0; k < subdomains.length; k++) {
subdomain = subdomains[k];
for (let m = 0; m < charset.length; m++) {
letter = charset[m];
temp.push(subdomain + letter);
}
}
subdomains = temp
}
return subdomains;
}
const subdomains = generateSubdomains(4);
Skrip ini akan menghasilkan setiap kemungkinan kombinasi
karakter dengan panjang n, dengan daftar karakter untuk menyusun
subdomain dari charset. Algoritme ini bekerja dengan membagi
string charset menjadi larik karakter, lalu menetapkan
set karakter awal ke larik karakter tersebut.
Selanjutnya, kami melakukan iterasi untuk durasi, membuat larik penyimpanan sementara di setiap iterasi. Kemudian kami melakukan iterasi untuk setiap subdomain, dan setiap karakter dalam larik charset yang menentukan set karakter yang tersedia. Terakhir, kami membangun larik temp menggunakan kombinasi subdomain dan huruf yang ada.
Sekarang, dengan menggunakan daftar subdomain ini, kita dapat mulai melakukan kueri terhadap domain tingkat atas (.com, .org., .net, dll.) seperti mega- bank.com. Untuk melakukannya, kita akan menulis skrip singkat yang memanfaatkan pustaka DNS yang disediakan dalam Node.js—sebuah runtime JavaScript yang populer.
Untuk menjalankan skrip ini, Anda hanya perlu menginstal Node.js versi terbaru di lingkungan Anda (dengan syarat lingkungan tersebut berbasis Unix seperti Linux atau Ubuntu):
const dns = require('dns');
const promises = [];
/*
* This list can be filled with the previous brute force
* script, or use a dictionary of common subdomains.
*/
const subdomains = [];
/*
* Iterate through each subdomain, and perform an asynchronous
* DNS query against each subdomain.
*
* This is much more performant than the more common `dns.lookup()`
* because `dns.lookup()` appears asynchronous from the JavaScript,
* but relies on the operating system's getaddrinfo(3) which is
* implemented synchronously.
*/
subdomains.forEach((subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err,ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
}));
});
// after all of the DNS queries have completed, log the
results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
Dalam skrip ini, kami melakukan beberapa hal untuk meningkatkan kejelasan dan kinerja kode brute forcing.
Pertama, impor pustaka DNS Node. Kemudian, kami membuat larik
promises, yang akan menyimpan daftar objek promise. Promises
adalah cara yang jauh lebih sederhana untuk menangani permintaan asinkron
dalam JavaScript, dan didukung secara native di setiap
peramban web utama dan Node.js.
Setelah ini, kami membuat larik lain bernama subdomains, yang
harus diisi dengan subdomain yang kami hasilkan dari
skrip pertama kami (kami akan menggabungkan kedua skrip tersebut di
akhir bagian ini). Selanjutnya, kami menggunakan operator forEach() untuk
dengan mudah mengiterasi setiap subdomain dalam larik subdomains.
Ini setara dengan iterasi for, tetapi secara sintaksis lebih
elegan.
Pada setiap level dalam iterasi subdomain, kami mendorong objek promise baru ke array promises. Dalam objek promise ini, kami memanggil dns.resolve, sebuah fungsi di pustaka DNS Node.js yang mencoba menyelesaikan nama domain ke alamat IP. Promise ini kami dorong ke array promise hanya setelah pustaka DNS menyelesaikan permintaan jaringannya.
Terakhir, blok Promise.all mengambil array objek promise dan menghasilkan (memanggil .then()) hanya ketika setiap promise di dalam array telah diselesaikan (menyelesaikan permintaan jaringannya).
Operator double !! dalam hasil menentukan bahwa kami hanya menginginkan hasil yang kembali terdefinisi, jadi kami harus mengabaikan upaya yang tidak mengembalikan alamat IP.
Jika kami menyertakan kondisi yang memanggil reject(), kami juga memerlukan blok catch() di akhir untuk menangani kesalahan. Pustaka DNS melempar sejumlah kesalahan, beberapa di antaranya mungkin tidak perlu dihentikan dengan brute force kami. Hal ini dihilangkan dari
contoh demi kesederhanaan,
tetapi akan menjadi latihan yang baik jika
Anda ingin melanjutkan contoh ini lebih jauh.
Selain itu, kami menggunakan dns.resolve dibandingkan dengan dns.lookup
karena meskipun implementasi JavaScript keduanya
diproses secara asinkron (terlepas dari urutan
pemanggilannya), implementasi asli yang diandalkan dns.lookup
dibangun di atas libuv yang menjalankan operasi secara sinkron.
Kami dapat menggabungkan kedua skrip tersebut menjadi satu program dengan sangat mudah. Pertama, kami membuat daftar subdomain potensial, lalu kami melakukan upaya brute force asinkron untuk menyelesaikan subdomain:
const dns = require('dns');
/*
* A simple function for brute forcing a list of subdomains
* given a maximum length of each subdomain.
*/
const generateSubdomains = function(length) {
/*
*
* A list of characters from which to generate subdomains.
* This can be altered to include less common characters
* like '-'.
*
* Chinese, Arabic, and Latin characters are also
* supported by some browsers.
*/
const charset = 'abcdefghijklmnopqrstuvwxyz' .split('');
let subdomains = charset;
let subdomain;
let letter;
let temp;
/*
* Time Complexity: o(n*m)
* n = length of string
* m = number of valid characters
*/
for (let i = 1; i < length; i++) {
temp = [];
for (let k = 0; k < subdomains.length; k++) {
subdomain = subdomains[k];
for (let m = 0; m < charset.length; m++) {
letter = charset[m];
temp.push(subdomain + letter);
}
}
subdomains = temp
}
return subdomains;
}
const subdomains = generateSubdomains(4);
const promises = [];
/*
*
* Iterate through each subdomain, and perform an asynchronous
* DNS query against each subdomain.
* This is much more performant than the more common `dns.lookup()`
* because `dns.lookup()` appears asynchronous from the JavaScript,
* but relies on the operating system's getaddrinfo(3) which is
* implemented synchronously.
*/
subdomains.forEach((subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
}));
});
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
Setelah menunggu sebentar, kita akan melihat daftar subdomain yang valid di terminal:
{ subdomain: 'mail', ip: '12.32.244.156' },
{ subdomain: 'admin', ip: '123.42.12.222' },
{ subdomain: 'dev', ip: '12.21.240.117' },
{ subdomain: 'test', ip: '14.34.27.119' },
{ subdomain: 'www', ip: '12.14.220.224' },
{ subdomain: 'shop', ip: '128.127.244.11' },
{ subdomain: 'ftp', ip: '12.31.222.212' },
{ subdomain: 'forum', ip: '14.15.78.136' }
Dictionary Attacks¶
Daripada mencoba setiap subdomain yang memungkinkan, kita dapat
mempercepat proses lebih lanjut dengan memanfaatkan dictionary attack
alih-alih serangan brute force. Layaknya serangan brute force,
serangan kamus mengiterasi beragam subdomain potensial
, tetapi alih-alih menghasilkannya secara acak, subdomain tersebut
ditarik dari daftar subdomain yang paling umum.
Serangan kamus jauh lebih cepat, dan biasanya akan menemukan sesuatu yang menarik. Hanya subdomain yang paling unik dan tidak standar yang akan disembunyikan dari serangan kamus.
Pemindai DNS sumber terbuka populer bernama dnscan mengirimkan daftar subdomain terpopuler di internet, berdasarkan jutaan subdomain dari lebih dari 86.000 catatan zona DNS. Menurut data pemindaian subdomain dari dnscan, 25 subdomain paling umum adalah sebagai berikut:
www
mail
ftp
localhost
webmail
smtp
pop
ns1
webdisk
ns2
cpanel
whm
autodiscover
autoconfig
m
imap
test
ns
blog
pop3
dev
www2
admin
forum
news
Repositori dnscan di GitHub menyimpan berkas-berkas yang berisi 10.000 subdomain teratas yang dapat diintegrasikan ke dalam proses rekon Anda berkat lisensi GNU v3 yang sangat terbuka. Anda dapat menemukan daftar subdomain dnscan dan kode sumbernya di GitHub.
Kita dapat dengan mudah memasukkan kamus seperti dnscan ke dalam skrip kita. Untuk
daftar yang lebih kecil, Anda cukup menyalin/menempel/mengkodekan string
ke dalam skrip. Untuk daftar yang besar, seperti daftar 10.000 subdomain
dnscan, kita harus memisahkan data dari skrip dan menariknya
saat runtime. Ini akan mempermudah modifikasi
daftar subdomain, atau penggunaan daftar subdomain lainnya. Sebagian besar
daftar ini akan berformat .csv, sehingga integrasi ke dalam skrip
rekon subdomain Anda menjadi sangat mudah:
const dns = require('dns');
const csv = require('csv-parser');
const fs = require('fs');
const promises = [];
/*
* Begin streaming the subdomain data from disk (versus
* pulling it all into memory at once, in case it is a large file).
*
* On each line, call `dns.resolve` to query the subdomain and
* check if it exists. Store these promises in the `promises` array.
*
* When all lines have been read, and all promises have been resolved,
* then log the subdomains found to the console.
*
* Performance Upgrade: if the subdomains list is exceptionally large,
* then a second file should be opened and the results should be
* streamed to that file whenever a promise resolves.
*/
fs.createReadStream('subdomains-10000.txt')
.pipe(csv())
.on('data', (subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
}));
})
.on('end', () => {
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
});
Ya, sesederhana itu! Jika Anda dapat menemukan kamus subdomain yang lengkap (hanya dengan satu pencarian), Anda dapat menempelkannya ke dalam skrip brute force, dan sekarang Anda memiliki skrip serangan kamus yang dapat digunakan juga.
Karena pendekatan kamus jauh lebih efisien daripada pendekatan brute force, mungkin bijaksana untuk memulai dengan kamus dan kemudian menggunakan pembangkitan subdomain brute force hanya jika kamus tidak memberikan hasil yang Anda cari.
Ringkasan¶
Saat melakukan pengintaian terhadap aplikasi web, tujuan utama seharusnya adalah membangun peta aplikasi yang dapat digunakan nanti saat memprioritaskan dan menyebarkan muatan serangan. Komponen awal dari pencarian ini adalah memahami server mana yang bertanggung jawab untuk menjaga aplikasi tetap berfungsi—oleh karena itu kami mencari subdomain yang terhubung ke domain utama suatu aplikasi.
Domain yang berhadapan dengan konsumen, seperti klien situs web perbankan, biasanya mendapatkan pengawasan paling ketat. Bug akan diperbaiki dengan cepat, karena pengunjung terpapar setiap hari.
Server yang berjalan di balik layar, seperti server email atau pintu belakang admin, sering kali dipenuhi bug karena penggunaan dan paparannya jauh lebih sedikit. Seringkali, menemukan salah satu API "di balik layar" ini dapat menjadi langkah awal yang bermanfaat saat mencari kerentanan untuk dieksploitasi dalam suatu aplikasi.
Sejumlah teknik sebaiknya digunakan saat mencoba menemukan subdomain, karena satu teknik mungkin tidak memberikan hasil yang komprehensif. Setelah Anda yakin telah melakukan pengintaian yang memadai dan mengumpulkan beberapa subdomain untuk domain yang Anda uji, Anda dapat beralih ke teknik pengintaian lainnya — tetapi Anda selalu dipersilakan untuk kembali dan mencari lebih banyak lagi jika Anda tidak berhasil dengan vektor serangan yang lebih jelas.