Scale dari Nol hingga Jutaan Pengguna¶
Merancang sistem yang mendukung jutaan pengguna merupakan tantangan, dan ini merupakan perjalanan yang membutuhkan penyempurnaan berkelanjutan dan peningkatan tanpa henti. Dalam bab ini, kita akan membangun sistem yang mendukung satu pengguna dan secara bertahap meningkatkannya untuk melayani jutaan pengguna. Setelah membaca bab ini, Anda akan menguasai beberapa teknik yang akan membantu Anda menjawab pertanyaan wawancara desain sistem.
Pengaturan Server Tunggal¶
Perjalanan seribu mil dimulai dengan satu langkah, dan membangun sistem yang kompleks pun demikian. Untuk memulai dengan sesuatu yang sederhana, semuanya berjalan pada satu server. Gambar 1 menunjukkan ilustrasi pengaturan server tunggal di mana semuanya berjalan pada satu server: aplikasi web, basis data, cache, dll.
Gambar 1¶
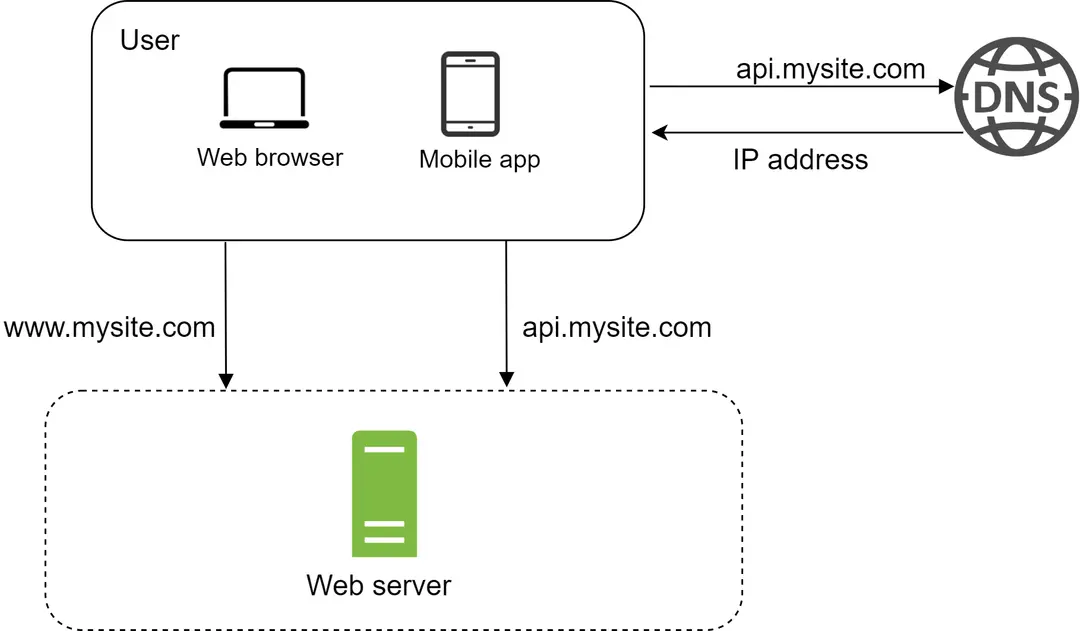
Untuk memahami pengaturan ini, ada baiknya untuk menyelidiki alur permintaan dan sumber lalu lintas. Mari kita lihat alur permintaan terlebih dahulu (Gambar 2).
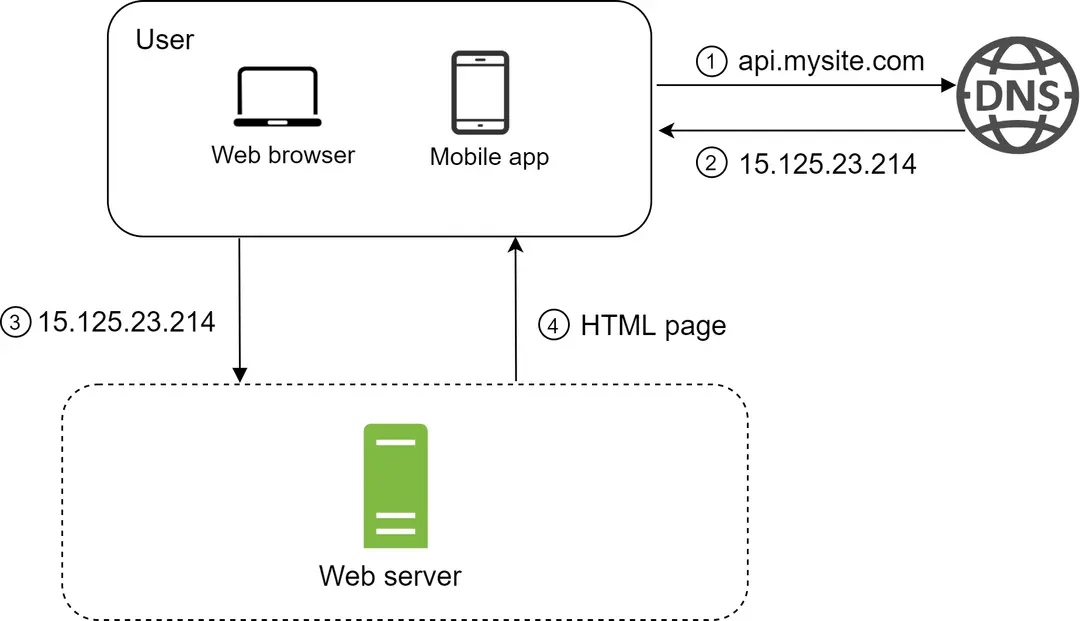
Gambar 2¶
Pengguna mengakses situs web melalui nama domain, seperti api.mysite.com. Biasanya, Sistem Nama Domain (DNS) adalah layanan berbayar yang disediakan oleh pihak ketiga dan tidak dihosting oleh server kami.
Alamat Protokol Internet (IP) dikembalikan ke peramban atau aplikasi seluler. Dalam contoh ini, alamat IP 15.125.23.214 dikembalikan.
Setelah alamat IP diperoleh, permintaan Protokol Transfer Hiperteks (HTTP) [1] dikirim langsung ke server web Anda.
Server web mengembalikan halaman HTML atau respons JSON untuk dirender.
Selanjutnya, mari kita periksa sumber lalu lintas. Lalu lintas ke server web Anda berasal dari dua sumber: aplikasi web dan aplikasi seluler.
Aplikasi web: menggunakan kombinasi bahasa sisi server (Java, Python, dll.) untuk menangani logika bisnis, penyimpanan, dll., dan bahasa sisi klien (HTML dan JavaScript) untuk presentasi.
Aplikasi seluler: Protokol HTTP adalah protokol komunikasi antara aplikasi seluler dan server web. Notasi Objek JavaScript (JSON) adalah format respons API yang umum digunakan untuk mentransfer data karena kesederhanaannya. Contoh respons API dalam format JSON ditunjukkan di bawah ini:
GET /users/12 – Retrieve user object for id = 12
{
"id":12,
"firstName":"John",
"lastName":"Smith",
"address":{
"streetAddress":"21 2nd Street",
"city":"New York",
"state":"NY",
"postalCode":10021
},
"phoneNumbers":[
"212 555-1234",
"646 555-4567"
]
}
Basis Data¶
Dengan pertumbuhan basis pengguna, satu server saja tidak cukup, dan kita membutuhkan beberapa server: satu untuk lalu lintas web/seluler, yang lainnya untuk basis data (Gambar 3). Memisahkan server lalu lintas web/seluler (tingkat web) dan basis data (tingkat data) memungkinkan keduanya untuk diskalakan secara independen.
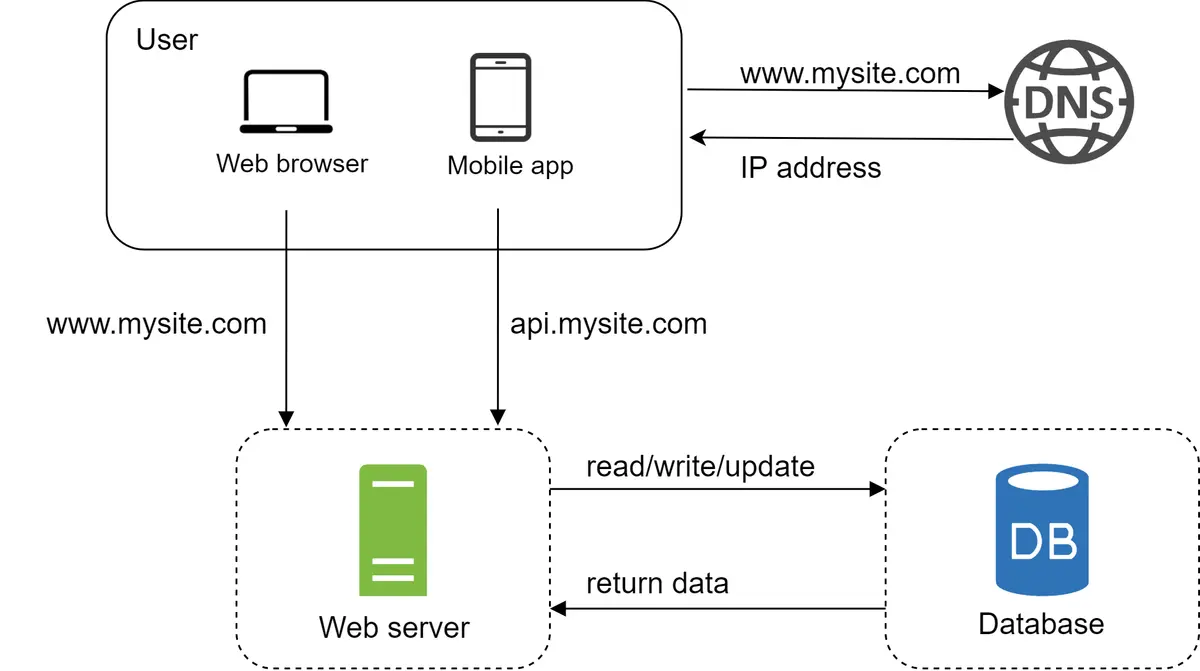
Gambar 3¶
Basis data mana yang harus digunakan?¶
Anda dapat memilih antara basis data relasional tradisional dan basis data non-relasional. Mari kita telaah perbedaannya.
Basis data relasional juga disebut sistem manajemen basis data relasional (RDBMS) atau basis data SQL. Yang paling populer adalah MySQL, basis data Oracle, PostgreSQL, dll. Basis data relasional merepresentasikan dan menyimpan data dalam tabel dan baris. Anda dapat melakukan operasi penggabungan menggunakan SQL di berbagai tabel basis data.
Basis data non-relasional juga disebut basis data NoSQL. Yang populer adalah CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB, dll. [2]. Basis data ini dikelompokkan menjadi empat kategori: penyimpanan kunci-nilai, penyimpanan grafik, penyimpanan kolom, dan penyimpanan dokumen. Operasi penggabungan umumnya tidak didukung dalam basis data non-relasional.
Bagi sebagian besar pengembang, basis data relasional adalah pilihan terbaik karena telah ada selama lebih dari 40 tahun dan secara historis telah berfungsi dengan baik. Namun, jika basis data relasional tidak cocok untuk kasus penggunaan spesifik Anda, penting untuk mengeksplorasi lebih dari sekadar basis data relasional. Basis data non-relasional mungkin merupakan pilihan yang tepat jika:
Aplikasi Anda membutuhkan latensi yang sangat rendah.
Data Anda tidak terstruktur, atau Anda tidak memiliki data relasional.
Anda hanya perlu melakukan serialisasi dan deserialisasi data (JSON, XML, YAML, dll.).
Anda perlu menyimpan data dalam jumlah besar.
Vertical scaling vs. Horizontal scaling¶
Penskalaan vertikal (Vertical scaling), yang disebut "scale up", berarti proses penambahan daya (CPU, RAM, dll.) ke server Anda. Penskalaan horizontal, yang disebut "scale-out", memungkinkan Anda melakukan penskalaan dengan menambahkan lebih banyak server ke dalam kumpulan sumber daya Anda.
Ketika lalu lintas rendah, penskalaan vertikal adalah pilihan yang tepat, dan kesederhanaan penskalaan vertikal merupakan keunggulan utamanya. Sayangnya, penskalaan vertikal memiliki keterbatasan yang serius.
Penskalaan vertikal memiliki batasan yang ketat. Mustahil untuk menambahkan CPU dan memori tanpa batas ke satu server.
Penskalaan vertikal tidak memiliki failover dan redundansi. Jika satu server mati, situs web/aplikasi juga ikut mati.
Penskalaan horizontal (Horizontal scaling) lebih disukai untuk aplikasi berskala besar karena keterbatasan penskalaan vertikal.
Pada desain sebelumnya, pengguna terhubung langsung ke server web. Pengguna tidak akan dapat mengakses situs web jika server web sedang offline. Dalam skenario lain, jika banyak pengguna mengakses server web secara bersamaan dan mencapai batas beban server web, pengguna umumnya mengalami respons yang lebih lambat atau gagal terhubung ke server. Penyeimbang beban adalah teknik terbaik untuk mengatasi masalah ini.
Load Balancer¶
Penyeimbang beban (Load Balancer) mendistribusikan lalu lintas masuk secara merata di antara server web yang ditentukan dalam rangkaian penyeimbang beban. Gambar 4 menunjukkan cara kerja penyeimbang beban.
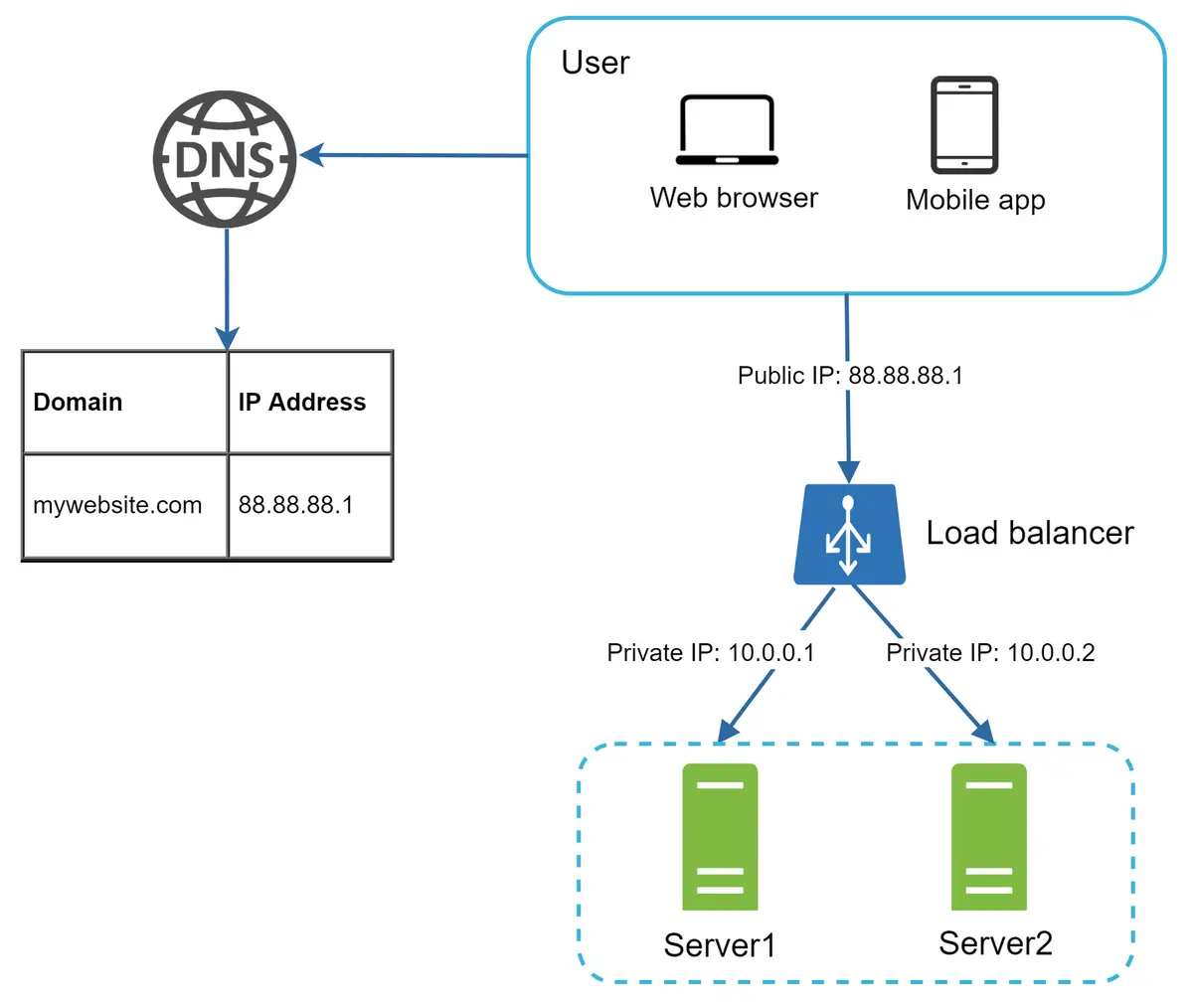
Gambar 4¶
Seperti yang ditunjukkan pada Gambar 4, pengguna terhubung langsung ke IP publik penyeimbang beban. Dengan pengaturan ini, server web tidak lagi dapat diakses langsung oleh klien. Untuk keamanan yang lebih baik, IP privat digunakan untuk komunikasi antar server. IP privat adalah alamat IP yang hanya dapat diakses antar server dalam jaringan yang sama; namun, tidak dapat diakses melalui internet. Penyeimbang beban berkomunikasi dengan server web melalui IP privat.
Pada Gambar 4, setelah penyeimbang beban dan server web kedua ditambahkan, kami berhasil mengatasi masalah tanpa failover dan meningkatkan ketersediaan tingkat web. Detailnya dijelaskan di bawah ini:
Jika server 1 offline, semua lalu lintas akan dialihkan ke server 2. Hal ini mencegah situs web offline. Kami juga akan menambahkan server web baru yang sehat ke kumpulan server untuk menyeimbangkan beban.
Jika lalu lintas situs web meningkat pesat, dan dua server tidak cukup untuk menangani lalu lintas tersebut, penyeimbang beban dapat menangani masalah ini dengan baik. Anda hanya perlu menambahkan lebih banyak server ke kumpulan server web, dan penyeimbang beban secara otomatis akan mulai mengirimkan permintaan kepada mereka.
Web tier-nya sudah terlihat bagus, bagaimana dengan data tier-nya? Desain saat ini hanya memiliki satu basis data, sehingga tidak mendukung failover dan redundansi. Replikasi basis data merupakan teknik umum untuk mengatasi masalah tersebut. Mari kita lihat.
Replikasi Database¶
Dikutip dari Wikipedia: “Replikasi basis data dapat digunakan di banyak sistem manajemen basis data, biasanya dengan hubungan master/slave antara basis data asli (master) dan salinannya (slave)” [3].
Basis data master umumnya hanya mendukung operasi tulis. Basis data slave menerima salinan data dari basis data master dan hanya mendukung operasi baca. Semua perintah pengubah data seperti sisip, hapus, atau perbarui harus dikirim ke basis data master. Sebagian besar aplikasi memerlukan rasio baca dan tulis yang jauh lebih tinggi; oleh karena itu, jumlah basis data slave dalam suatu sistem biasanya lebih besar daripada jumlah basis data master. Gambar 5 menunjukkan basis data master dengan beberapa basis data slave.

Gambar 5¶
Keuntungan replikasi basis data:
Better performance Performa yang lebih baik: Dalam model master-slave, semua penulisan dan pembaruan terjadi di node master; sedangkan, operasi baca didistribusikan ke seluruh node slave. Model ini meningkatkan performa karena memungkinkan lebih banyak kueri diproses secara paralel.
Reliability Keandalan: Jika salah satu server basis data Anda hancur akibat bencana alam, seperti topan atau gempa bumi, data tetap terlindungi. Anda tidak perlu khawatir kehilangan data karena data direplikasi di beberapa lokasi.
High availability Ketersediaan tinggi: Dengan mereplikasi data di berbagai lokasi, situs web Anda tetap beroperasi meskipun basis data sedang offline karena Anda dapat mengakses data yang tersimpan di server basis data lain.
Di bagian sebelumnya, kita membahas bagaimana penyeimbang beban membantu meningkatkan ketersediaan sistem. Kita juga mengajukan pertanyaan yang sama di sini: bagaimana jika salah satu basis data offline? Desain arsitektur yang dibahas pada Gambar 5 dapat menangani kasus ini:
Jika hanya satu basis data slave yang tersedia dan offline, operasi baca akan dialihkan ke basis data master untuk sementara. Segera setelah masalah ditemukan, basis data slave yang baru akan menggantikan yang lama. Jika terdapat beberapa basis data slave yang tersedia, operasi baca dialihkan ke basis data slave lain yang masih berfungsi. Server basis data baru akan menggantikan yang lama.
Jika basis data master offline, basis data slave akan dipromosikan menjadi master baru. Semua operasi basis data akan dijalankan sementara pada basis data master yang baru. Basis data slave yang baru akan segera menggantikan yang lama untuk replikasi data. Dalam sistem produksi, mempromosikan master baru lebih rumit karena data dalam basis data slave mungkin tidak mutakhir. Data yang hilang perlu diperbarui dengan menjalankan skrip pemulihan data. Meskipun beberapa metode replikasi lain seperti multi-master dan replikasi sirkular dapat membantu, pengaturan tersebut lebih rumit; dan pembahasannya berada di luar cakupan kursus ini. Pembaca yang tertarik disarankan untuk merujuk pada materi referensi yang tercantum [4] [5].
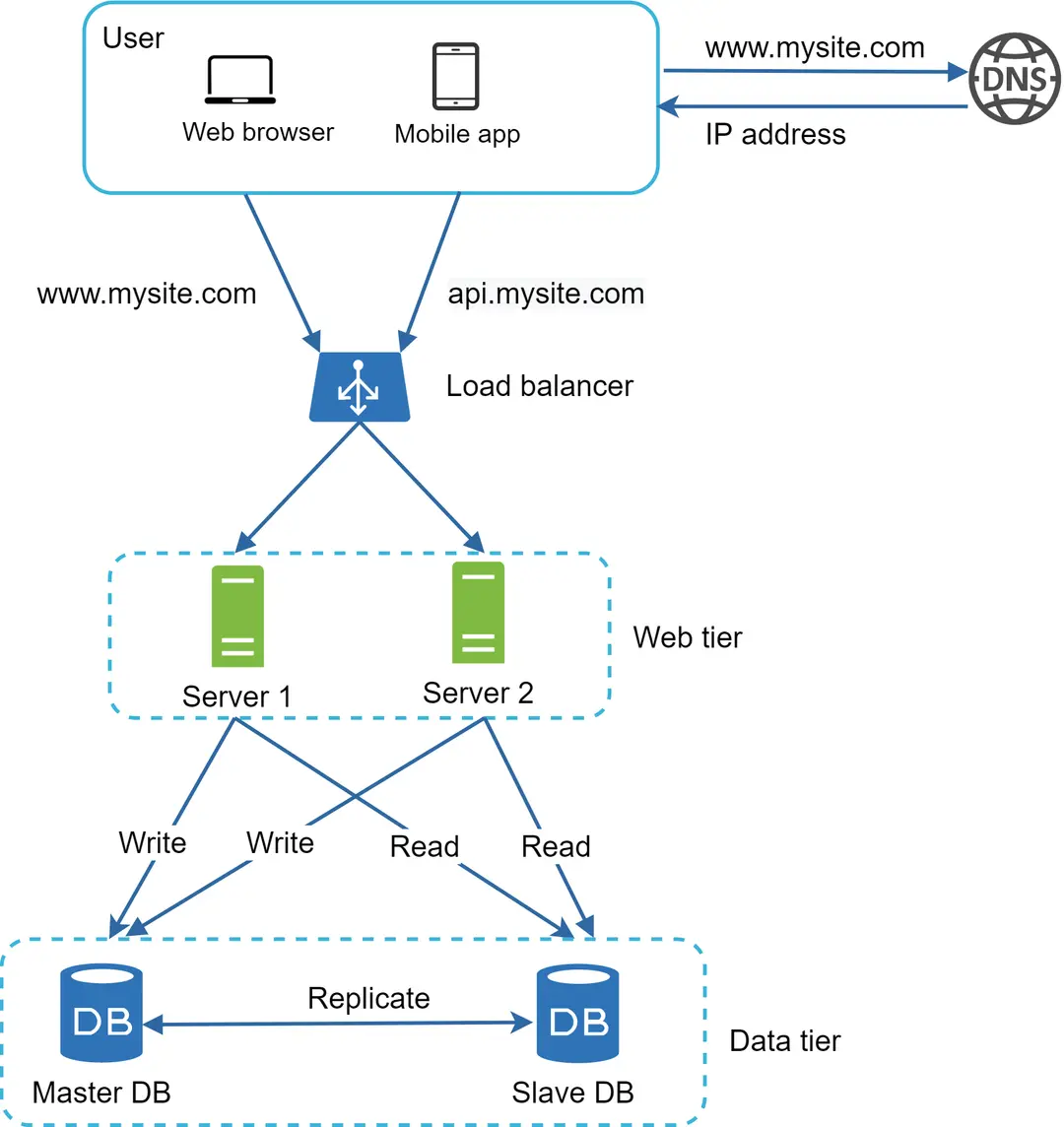
Gambar 6 menunjukkan desain sistem setelah menambahkan penyeimbang beban dan replikasi basis data.
Gambar 6¶
Mari kita lihat desainnya:
Pengguna mendapatkan alamat IP penyeimbang beban dari DNS.
Pengguna menghubungkan penyeimbang beban dengan alamat IP ini.
Permintaan HTTP dirutekan ke Server 1 atau Server 2.
Server web membaca data pengguna dari basis data slave.
Server web merutekan semua operasi modifikasi data ke basis data master. Ini termasuk operasi tulis, perbarui, dan hapus.
Sekarang, Anda telah memahami web dan tingkatan data dengan baik, saatnya untuk meningkatkan waktu muat/respons. Hal ini dapat dilakukan dengan menambahkan lapisan cache dan mengalihkan konten statis (berkas JavaScript/CSS/gambar/video) ke jaringan pengiriman konten (CDN).
Cache¶
Cache adalah area penyimpanan sementara yang menyimpan hasil respons yang mahal atau data yang sering diakses di dalam memori sehingga permintaan selanjutnya dapat dilayani lebih cepat. Seperti yang diilustrasikan pada Gambar 6, setiap kali halaman web baru dimuat, satu atau beberapa panggilan basis data dieksekusi untuk mengambil data. Performa aplikasi sangat terpengaruh oleh pemanggilan basis data berulang kali. Cache dapat mengatasi masalah ini.
Cache tier¶
The cache tier is a temporary data store layer, much faster than the database. The benefits of having a separate cache tier include better system performance, ability to reduce database workloads, and the ability to scale the cache tier independently. Figure 7 shows a possible setup of a cache server:

Gambar 7¶
Setelah menerima permintaan, server web pertama-tama memeriksa apakah cache memiliki respons yang tersedia. Jika tersedia, server akan mengirimkan data kembali ke klien. Jika tidak, server akan melakukan kueri ke basis data, menyimpan respons dalam cache, dan mengirimkannya kembali ke klien. Strategi caching ini disebut read-through cache. Strategi caching lainnya tersedia tergantung pada tipe data, ukuran, dan pola akses. Sebuah studi sebelumnya menjelaskan cara kerja berbagai strategi caching [6].
Berinteraksi dengan server cache mudah karena sebagian besar server cache menyediakan API untuk bahasa pemrograman umum. Cuplikan kode berikut menunjukkan API Memcached yang umum:
DETIK = 1
cache.set('myKey, 'hi there', 3600 * DETIK)
cache.get('myKey')
Pertimbangan dalam penggunaan cache¶
Berikut beberapa pertimbangan dalam penggunaan sistem cache:
Tentukan kapan akan menggunakan cache. Pertimbangkan untuk menggunakan cache ketika data sering dibaca tetapi jarang dimodifikasi. Karena data cache disimpan dalam memori volatil, server cache tidak ideal untuk menyimpan data persisten. Misalnya, jika server cache dimulai ulang, semua data di memori akan hilang. Oleh karena itu, data penting harus disimpan dalam penyimpanan data persisten.
Expiration policy Kebijakan kedaluwarsa. Menerapkan kebijakan kedaluwarsa merupakan praktik yang baik. Setelah data cache kedaluwarsa, data tersebut akan dihapus dari cache. Jika tidak ada kebijakan kedaluwarsa, data cache akan disimpan secara permanen di memori. Disarankan untuk tidak membuat tanggal kedaluwarsa terlalu pendek karena hal ini akan menyebabkan sistem memuat ulang data dari basis data terlalu sering. Sementara itu, disarankan untuk tidak membuat tanggal kedaluwarsa terlalu panjang karena data dapat menjadi basi.
Consistency Konsistensi: Ini melibatkan sinkronisasi penyimpanan data dan cache. Ketidakkonsistenan dapat terjadi karena operasi modifikasi data pada penyimpanan data dan cache tidak dilakukan dalam satu transaksi. Saat melakukan penskalaan di beberapa wilayah, menjaga konsistensi antara penyimpanan data dan cache merupakan tantangan. Untuk detail lebih lanjut, silakan merujuk pada makalah berjudul "Scaling Memcache at Facebook" yang diterbitkan oleh Facebook [7].
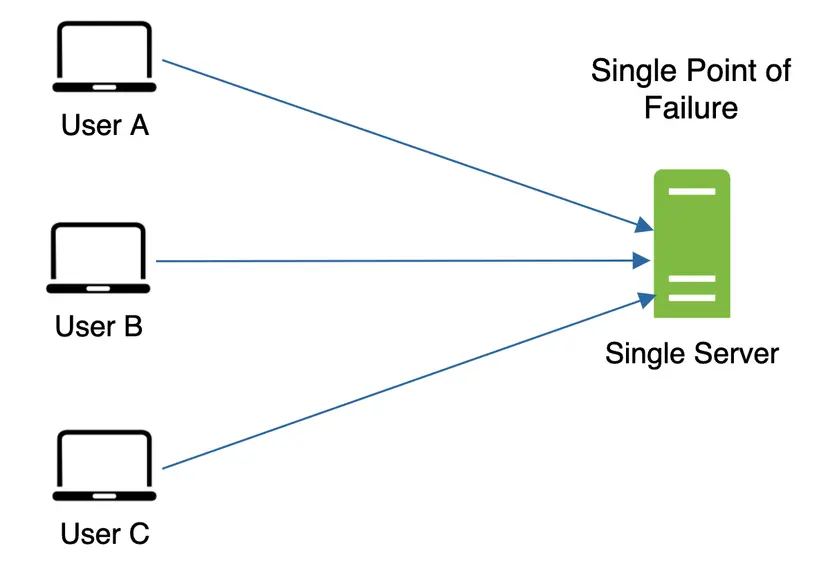
Mitigating failures Mitigasi kegagalan: Satu server cache tunggal mewakili potensi titik kegagalan tunggal (SPOF), yang didefinisikan di Wikipedia sebagai berikut: "Satu titik kegagalan tunggal (SPOF) adalah bagian dari sistem yang, jika gagal, akan menghentikan seluruh sistem agar tidak berfungsi" [8]. Oleh karena itu, disarankan untuk menggunakan beberapa server cache di berbagai pusat data untuk menghindari SPOF. Pendekatan lain yang disarankan adalah menyediakan memori yang dibutuhkan secara berlebihan dengan persentase tertentu. Ini akan menyediakan buffer seiring dengan peningkatan penggunaan memori.
Gambar 8¶
Eviction Policy Kebijakan Pengusiran: Setelah cache penuh, permintaan untuk menambahkan item ke cache dapat menyebabkan item yang ada dihapus. Ini disebut pengusiran cache. Kebijakan pengusiran cache yang paling umum adalah Least-recently-used (LRU). Kebijakan pengusiran lainnya, seperti Least Frequently Used (LFU) atau First in First Out (FIFO), dapat diadopsi untuk memenuhi berbagai kasus penggunaan.
Content delivery network (CDN)¶
CDN adalah jaringan server yang tersebar secara geografis dan digunakan untuk mengirimkan konten statis. Server CDN menyimpan konten statis seperti gambar, video, CSS, berkas JavaScript, dll. dalam cache.
Caching konten dinamis adalah konsep yang relatif baru dan berada di luar cakupan kursus ini. Konsep ini memungkinkan caching halaman HTML berdasarkan jalur permintaan, string kueri, kuki, dan header permintaan. Silakan merujuk ke artikel yang disebutkan dalam materi referensi [9] untuk informasi lebih lanjut. Kursus ini berfokus pada cara menggunakan CDN untuk menyimpan konten statis dalam cache.
Beginilah cara kerja CDN secara umum: ketika pengguna mengunjungi situs web, server CDN yang paling dekat dengan pengguna akan mengirimkan konten statis. Secara intuitif, semakin jauh pengguna dari server CDN, semakin lambat situs web dimuat. Misalnya, jika server CDN berada di San Francisco, pengguna di Los Angeles akan mendapatkan konten lebih cepat daripada pengguna di Eropa. Gambar 9 adalah contoh yang bagus yang menunjukkan bagaimana CDN meningkatkan waktu muat.

Gambar 9¶
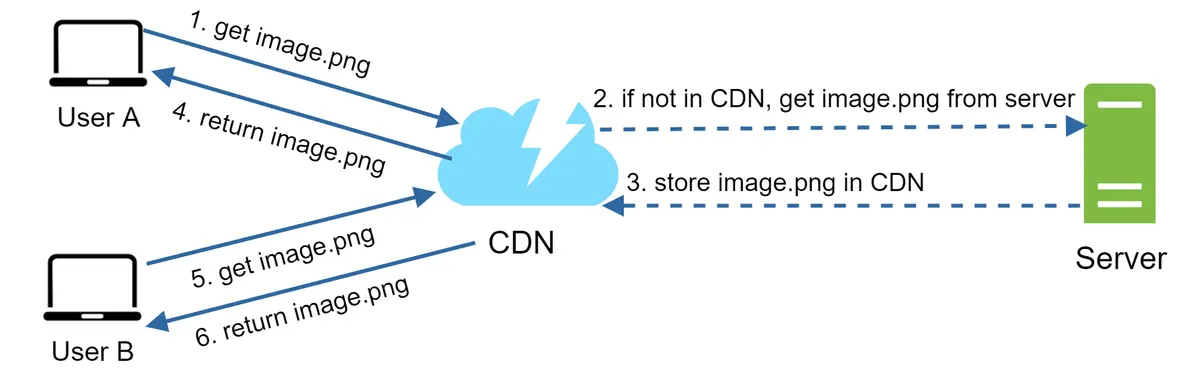
Gambar 10 menunjukkan alur kerja CDN.
Gambar 10¶
- Pengguna A mencoba mendapatkan image.png menggunakan URL gambar. Domain URL disediakan oleh penyedia CDN. Dua URL gambar berikut adalah contoh yang digunakan untuk menunjukkan tampilan URL gambar di CDN Amazon dan Akamai:
Jika server CDN tidak memiliki image.png dalam cache, server CDN akan meminta berkas tersebut dari server asal, yang dapat berupa server web atau penyimpanan daring seperti Amazon S3.
Server asal akan mengembalikan image.png ke server CDN, yang menyertakan header HTTP opsional Time-to-Live (TTL) yang menjelaskan lamanya gambar di-cache.
CDN akan men-cache gambar dan mengembalikannya ke Pengguna A. Gambar tersebut tetap di-cache di CDN hingga TTL berakhir.
Pengguna B mengirimkan permintaan untuk mendapatkan gambar yang sama.
Gambar dikembalikan dari cache selama TTL belum kedaluwarsa.
{kind=link}
{kind=link}
Pertimbangan Penggunaan CDN¶
Biaya: CDN dijalankan oleh penyedia pihak ketiga, dan Anda dikenakan biaya untuk transfer data masuk dan keluar dari CDN. Menyimpan aset yang jarang digunakan dalam cache tidak memberikan manfaat yang signifikan, jadi Anda sebaiknya mempertimbangkan untuk memindahkannya dari CDN.
Menetapkan masa berlaku cache yang sesuai: Untuk konten yang sensitif terhadap waktu, menetapkan masa berlaku cache sangatlah penting. Masa berlaku cache tidak boleh terlalu lama atau terlalu singkat. Jika terlalu lama, konten tersebut mungkin tidak lagi baru. Jika terlalu singkat, dapat menyebabkan pemuatan ulang konten berulang kali dari server asal ke CDN.
CDN fallback: Anda harus mempertimbangkan bagaimana situs web/aplikasi Anda mengatasi kegagalan CDN. Jika terjadi pemadaman CDN sementara, klien seharusnya dapat mendeteksi masalah dan meminta sumber daya dari server asal.
Membatalkan berkas: Anda dapat menghapus berkas dari CDN sebelum kedaluwarsa dengan melakukan salah satu operasi berikut:
Membatalkan objek CDN menggunakan API yang disediakan oleh vendor CDN.
Gunakan pembuatan versi objek untuk menyajikan versi objek yang berbeda. Untuk membuat versi objek, Anda dapat menambahkan parameter ke URL, seperti nomor versi. Misalnya, nomor versi 2 ditambahkan ke string kueri: image.png?v=2.
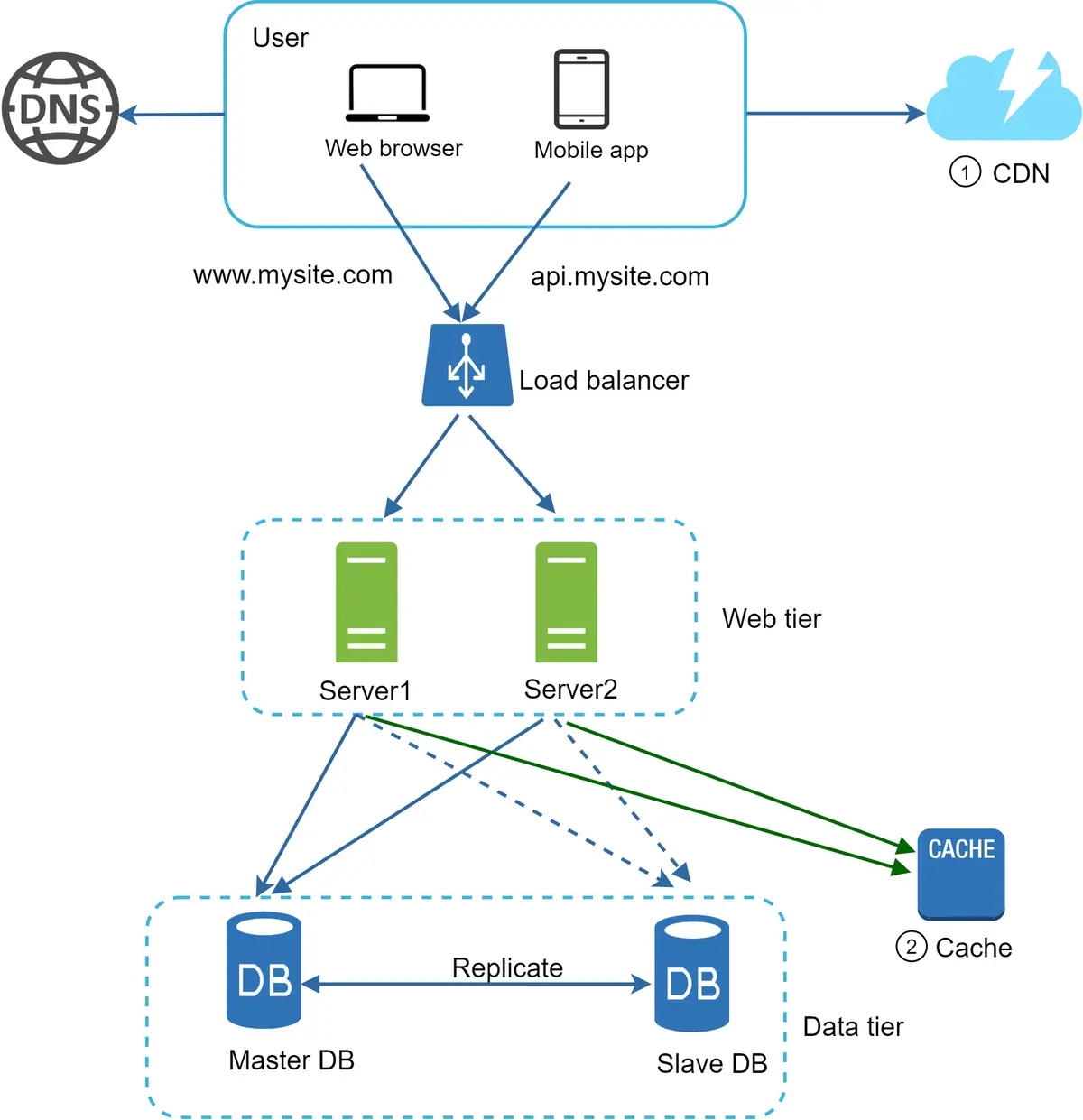
Gambar 11 menunjukkan desain setelah CDN dan cache ditambahkan.
Gambar 11¶
Aset statis (JS, CSS, gambar, dll.) tidak lagi dilayani oleh server web. Aset tersebut diambil dari CDN untuk kinerja yang lebih baik.
Beban basis data diringankan dengan menyimpan data dalam cache.
Stateless web tier¶
Sekarang saatnya mempertimbangkan penskalaan tingkat web secara horizontal. Untuk ini, kita perlu memindahkan status (misalnya data sesi pengguna) keluar dari tingkat web. Praktik yang baik adalah menyimpan data sesi dalam penyimpanan persisten seperti basis data relasional atau NoSQL. Setiap server web dalam klaster dapat mengakses data status dari basis data. Ini disebut tingkat web stateless.
Stateful architecture¶
Server stateful dan server stateless memiliki beberapa perbedaan utama. Server stateful mengingat data klien (status) dari satu permintaan ke permintaan berikutnya. Server stateless tidak menyimpan informasi status.
Gambar 12 menunjukkan contoh arsitektur stateful.
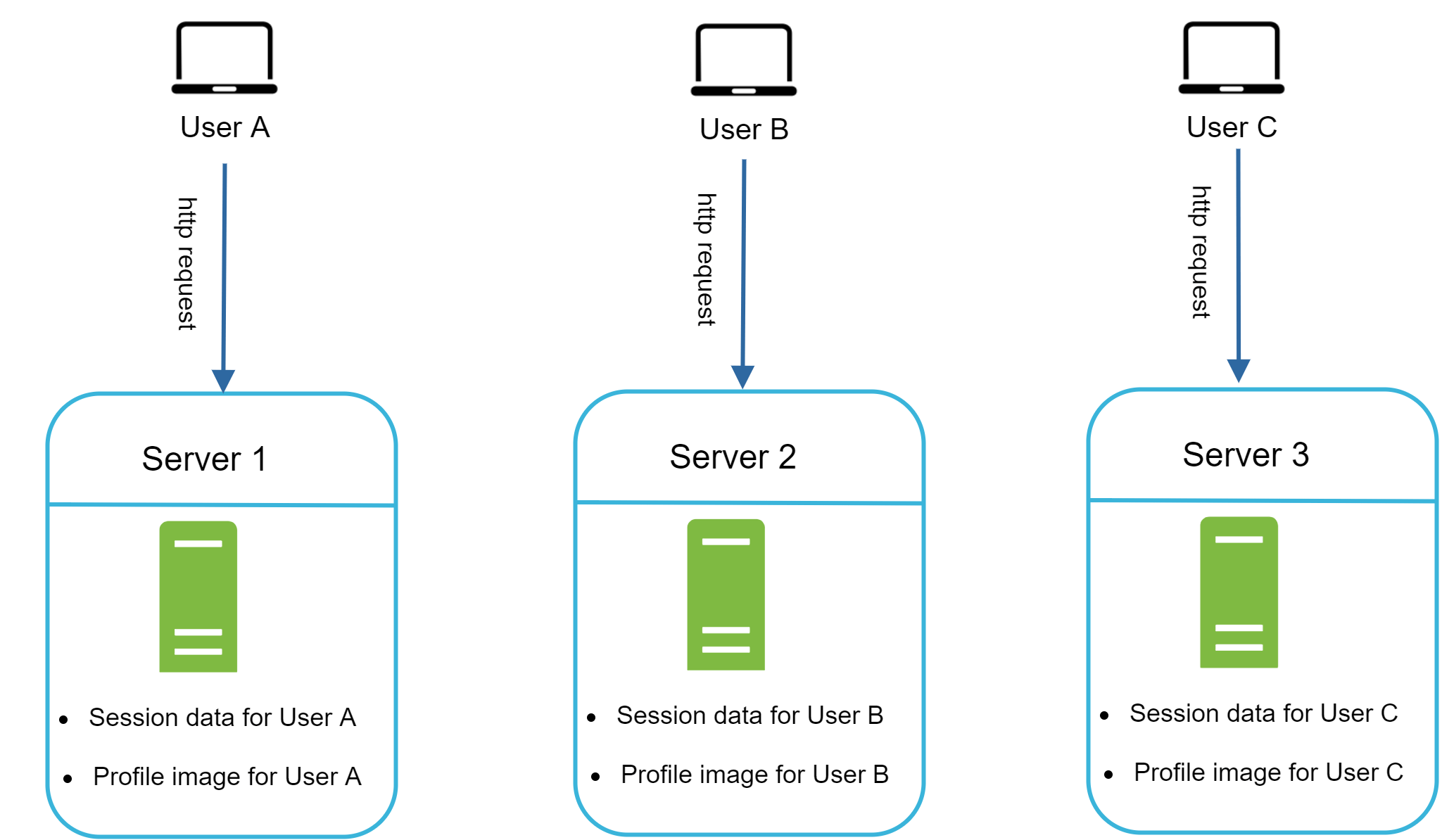
Gambar 12¶
Pada Gambar 12, data sesi dan gambar profil pengguna A disimpan di Server 1. Untuk mengautentikasi Pengguna A, permintaan HTTP harus dirutekan ke Server 1. Jika permintaan dikirim ke server lain seperti Server 2, autentikasi akan gagal karena Server 2 tidak berisi data sesi Pengguna A. Demikian pula, semua permintaan HTTP dari Pengguna B harus dirutekan ke Server 2; semua permintaan dari Pengguna C harus dikirim ke Server 3.
Masalahnya adalah setiap permintaan dari klien yang sama harus dirutekan ke server yang sama. Hal ini dapat dilakukan dengan sesi lengket di sebagian besar penyeimbang beban [10]; namun, hal ini menambah overhead. Menambah atau menghapus server jauh lebih sulit dengan pendekatan ini. Menangani kegagalan server juga menjadi tantangan.
Stateless architecture¶
Gambar 13 menunjukkan arsitektur stateless.
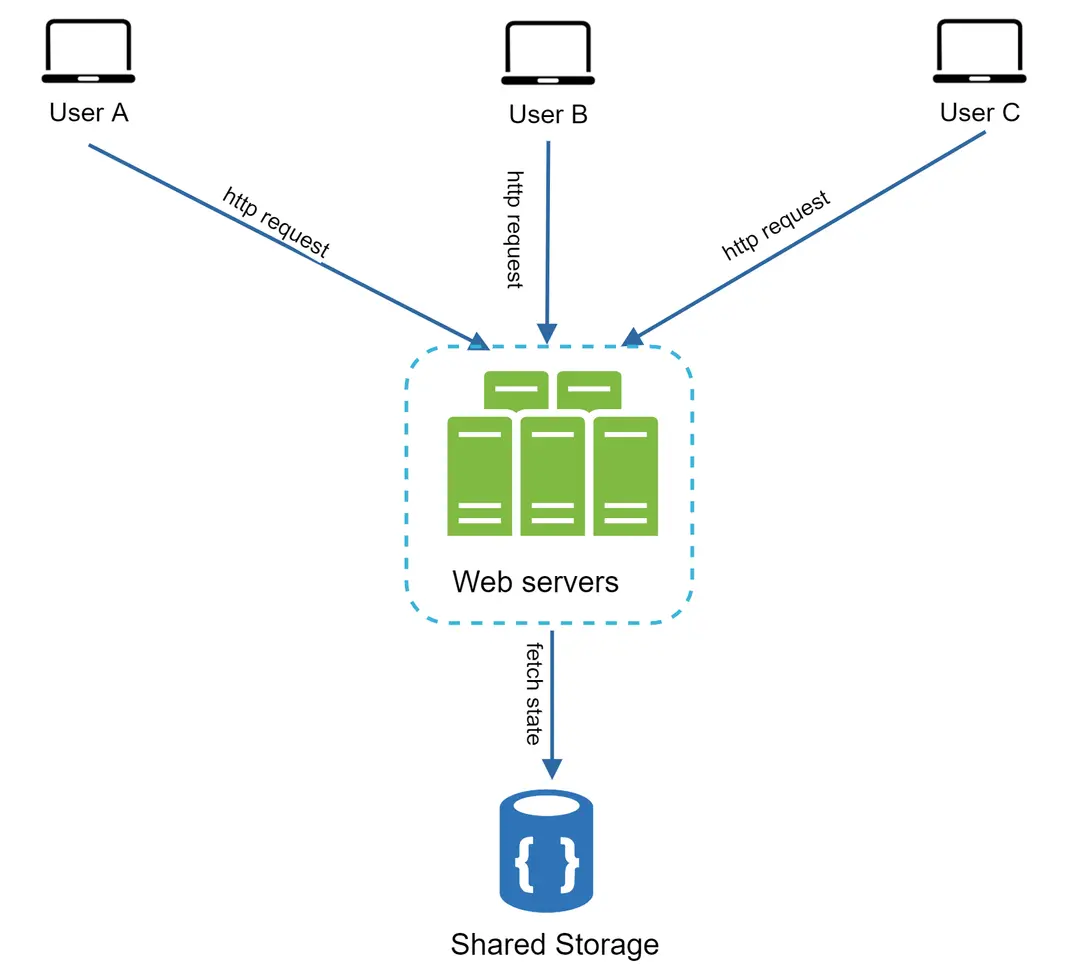
Gambar 13¶
Dalam arsitektur stateless ini, permintaan HTTP dari pengguna dapat dikirim ke server web mana pun, yang kemudian mengambil data status dari penyimpanan data bersama. Data status disimpan di penyimpanan data bersama dan tidak diakses oleh server web. Sistem stateless lebih sederhana, lebih tangguh, dan skalabel.
Gambar 14 menunjukkan desain yang diperbarui dengan web tier stateless.
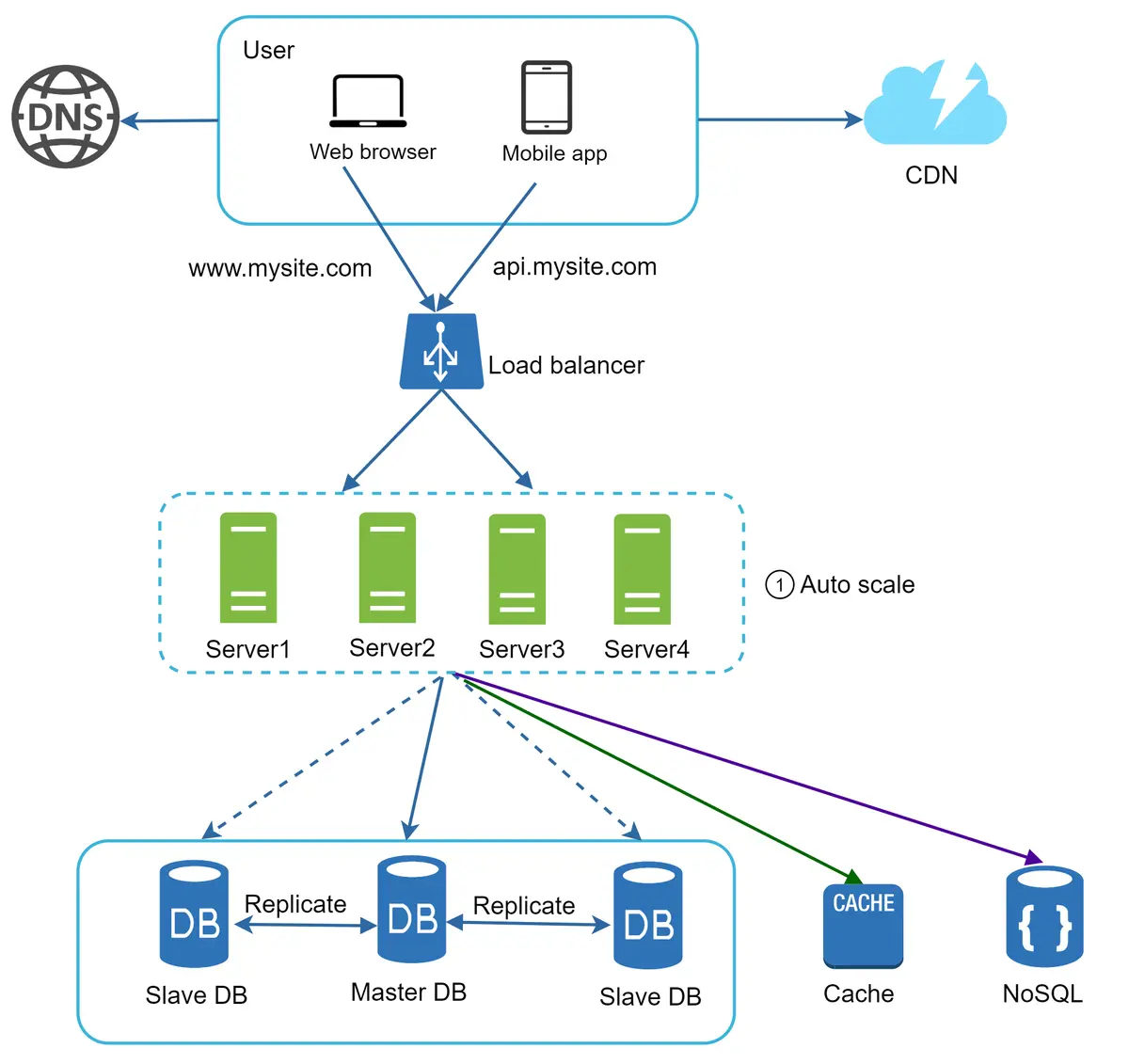
Gambar 14¶
Pada Gambar 14, kami memindahkan data sesi keluar dari web tier dan menyimpannya di penyimpanan data persisten. Penyimpanan data bersama dapat berupa basis data relasional, Memcached/Redis, NoSQL, dll. Penyimpanan data NoSQL dipilih karena mudah diskalakan. Penskalaan otomatis berarti menambahkan atau menghapus server web secara otomatis berdasarkan beban lalu lintas. Setelah data status dihapus dari server web, penskalaan otomatis web tier dapat dengan mudah dicapai dengan menambahkan atau menghapus server berdasarkan beban lalu lintas.
Situs web Anda berkembang pesat dan menarik banyak pengguna internasional. Untuk meningkatkan ketersediaan dan memberikan pengalaman pengguna yang lebih baik di wilayah geografis yang lebih luas, mendukung beberapa pusat data sangatlah penting.
Data Center¶
Gambar 15 menunjukkan contoh pengaturan dengan dua pusat data. Dalam operasi normal, pengguna dirutekan secara geoDNS, juga dikenal sebagai geo-routed, ke pusat data terdekat, dengan lalu lintas terbagi x% di AS Timur dan (100 – x)% di AS Barat. GeoDNS adalah layanan DNS yang memungkinkan nama domain diubah menjadi alamat IP berdasarkan lokasi pengguna.
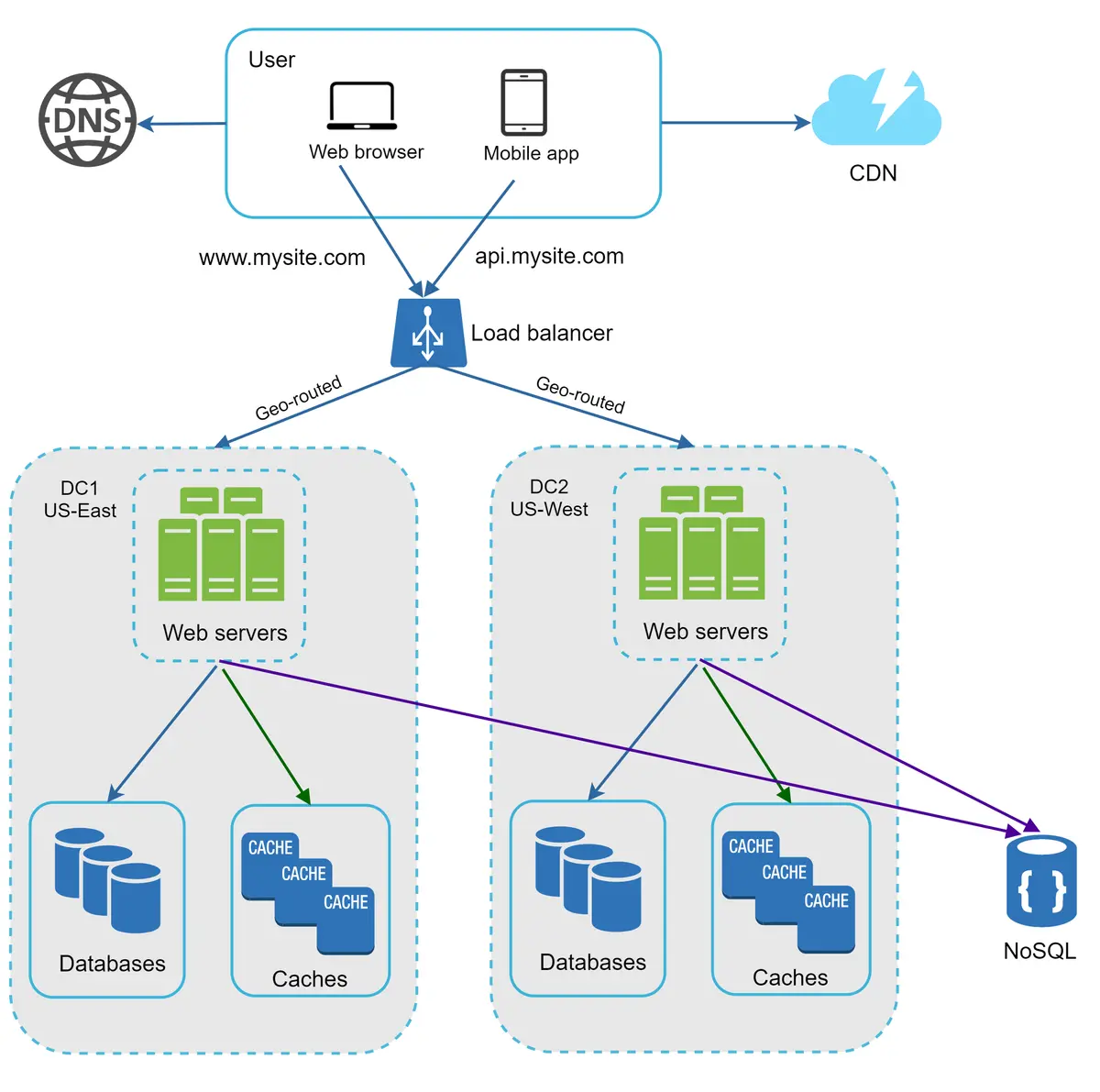
Gambar 15¶
Jika terjadi pemadaman pusat data yang signifikan, kami mengarahkan semua lalu lintas ke pusat data yang sehat. Pada Gambar 16, pusat data 2 (AS Barat) sedang offline, dan 100% lalu lintas dialihkan ke pusat data 1 (AS Timur).
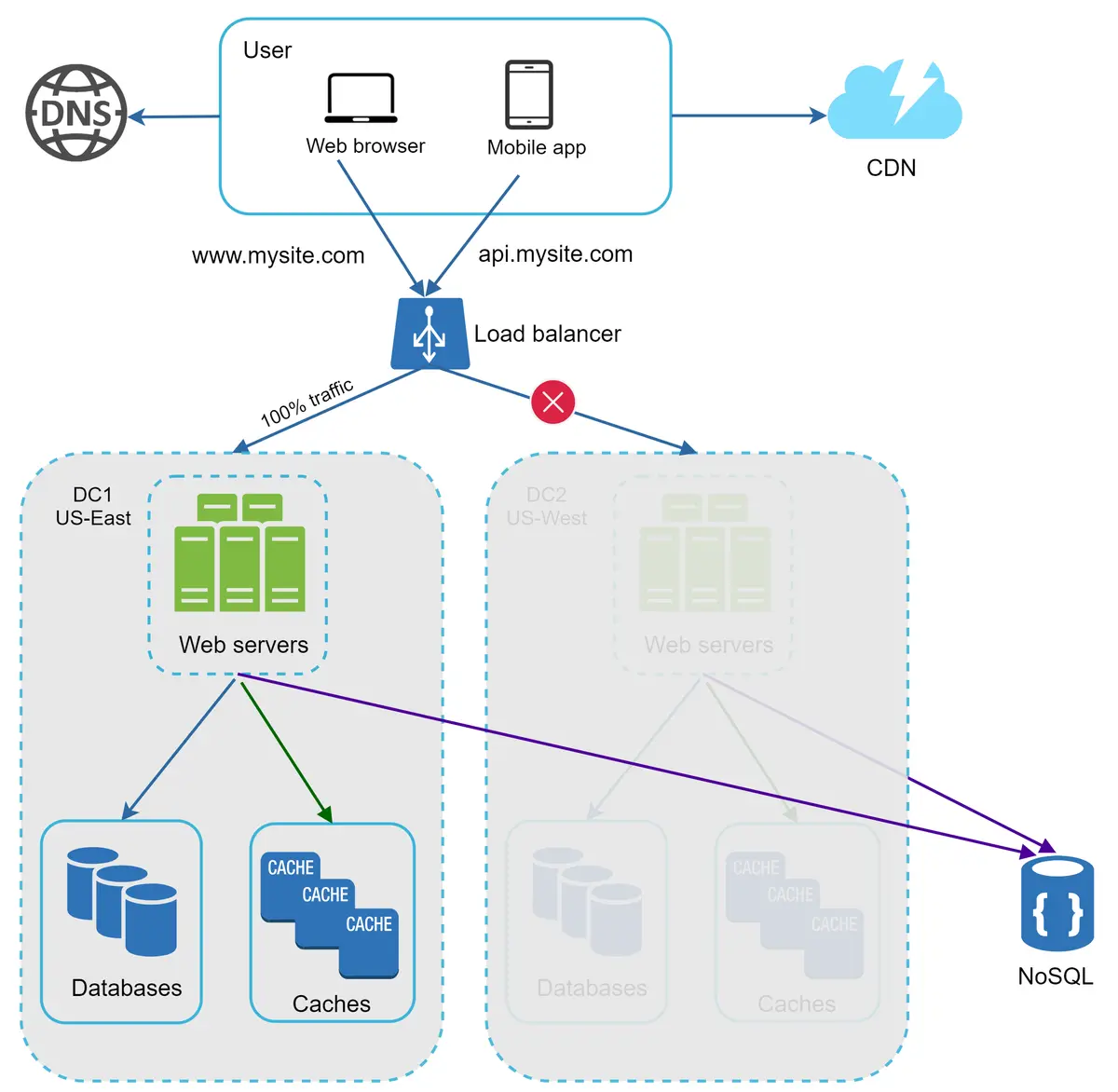
Gambar 16¶
Beberapa tantangan teknis harus diatasi untuk mencapai pengaturan multi-pusat data:
Pengalihan lalu lintas: Diperlukan alat yang efektif untuk mengarahkan lalu lintas ke pusat data yang tepat. GeoDNS dapat digunakan untuk mengarahkan lalu lintas ke pusat data terdekat, tergantung lokasi pengguna.
Sinkronisasi data: Pengguna dari berbagai wilayah dapat menggunakan basis data atau cache lokal yang berbeda. Dalam kasus failover, lalu lintas mungkin dialihkan ke pusat data yang datanya tidak tersedia. Strategi umum adalah mereplikasi data di beberapa pusat data. Sebuah studi sebelumnya menunjukkan bagaimana Netflix mengimplementasikan replikasi multi-pusat data asinkron [11].
Pengujian dan penerapan: Dengan pengaturan multi-pusat data, penting untuk menguji situs web/aplikasi Anda di berbagai lokasi. Alat penerapan otomatis sangat penting untuk menjaga konsistensi layanan di semua pusat data [11].
Untuk meningkatkan skala sistem kami, kami perlu memisahkan berbagai komponen sistem agar dapat diskalakan secara independen. Antrean pesan merupakan strategi utama yang digunakan oleh banyak sistem terdistribusi di dunia nyata untuk mengatasi masalah ini.
Message queue¶
Message queue Antrean pesan adalah komponen tahan lama yang tersimpan dalam memori dan mendukung komunikasi asinkron. Antrean pesan berfungsi sebagai buffer dan mendistribusikan permintaan asinkron. Arsitektur dasar antrean pesan sederhana. Layanan input, yang disebut produsen/penerbit, membuat pesan dan menerbitkannya ke antrean pesan. Layanan atau server lain, yang disebut konsumen/pelanggan, terhubung ke antrean dan melakukan tindakan yang ditentukan oleh pesan. Modelnya ditunjukkan pada Gambar 17.

Gambar 17¶
Pemisahan (decoupling) menjadikan antrean pesan sebagai arsitektur pilihan untuk membangun aplikasi yang skalabel dan andal. Dengan antrean pesan, produsen dapat mengirim pesan ke antrean saat konsumen tidak dapat memprosesnya. Konsumen dapat membaca pesan dari antrean bahkan saat produsen tidak dapat memprosesnya.
Pertimbangkan kasus penggunaan berikut: aplikasi Anda mendukung kustomisasi foto, termasuk pemotongan, penajaman, pemburaman, dll. Tugas kustomisasi tersebut membutuhkan waktu untuk diselesaikan. Pada Gambar 18, server web mempublikasikan pekerjaan pemrosesan foto ke antrean pesan. Pekerja pemrosesan foto mengambil pekerjaan dari antrean pesan dan secara asinkron melakukan tugas kustomisasi foto. Produsen dan konsumen dapat diskalakan secara independen. Ketika ukuran antrean menjadi besar, lebih banyak pekerja ditambahkan untuk mengurangi waktu pemrosesan. Namun, jika antrean kosong hampir sepanjang waktu, jumlah pekerja dapat dikurangi.

Gambar 18¶
Pencatatan log, metrik, otomatisasi¶
Saat bekerja dengan situs web kecil yang berjalan di beberapa server, pencatatan log, metrik, dan dukungan otomatisasi merupakan praktik yang baik, tetapi bukan suatu keharusan. Namun, karena situs Anda kini telah berkembang untuk melayani bisnis besar, berinvestasi pada alat-alat tersebut sangatlah penting.
Logging Pencatatan log: Memantau log kesalahan penting karena membantu mengidentifikasi kesalahan dan masalah dalam sistem. Anda dapat memantau log kesalahan di setiap tingkat server atau menggunakan alat untuk menggabungkannya ke layanan terpusat agar mudah dicari dan dilihat.
Metrics Metrik: Mengumpulkan berbagai jenis metrik membantu kami mendapatkan wawasan bisnis dan memahami status kesehatan sistem. Beberapa metrik berikut bermanfaat:
Metrik tingkat host: CPU, Memori, I/O disk, dll.
Metrik tingkat agregat: misalnya, kinerja seluruh tingkat basis data, tingkat cache, dll.
Metrik bisnis utama: pengguna aktif harian, retensi, pendapatan, dll.
Otomatisasi: Ketika sistem menjadi besar dan kompleks, kita perlu membangun atau memanfaatkan alat otomatisasi untuk meningkatkan produktivitas. Integrasi berkelanjutan adalah praktik yang baik, di mana setiap check-in kode diverifikasi melalui otomatisasi, yang memungkinkan tim mendeteksi masalah lebih dini. Selain itu, mengotomatiskan proses build, pengujian, penerapan, dll. dapat meningkatkan produktivitas pengembang secara signifikan.
Menambahkan antrean pesan dan berbagai alat
Gambar 19 menunjukkan desain yang diperbarui. Karena keterbatasan ruang, hanya satu pusat data yang ditampilkan pada gambar.
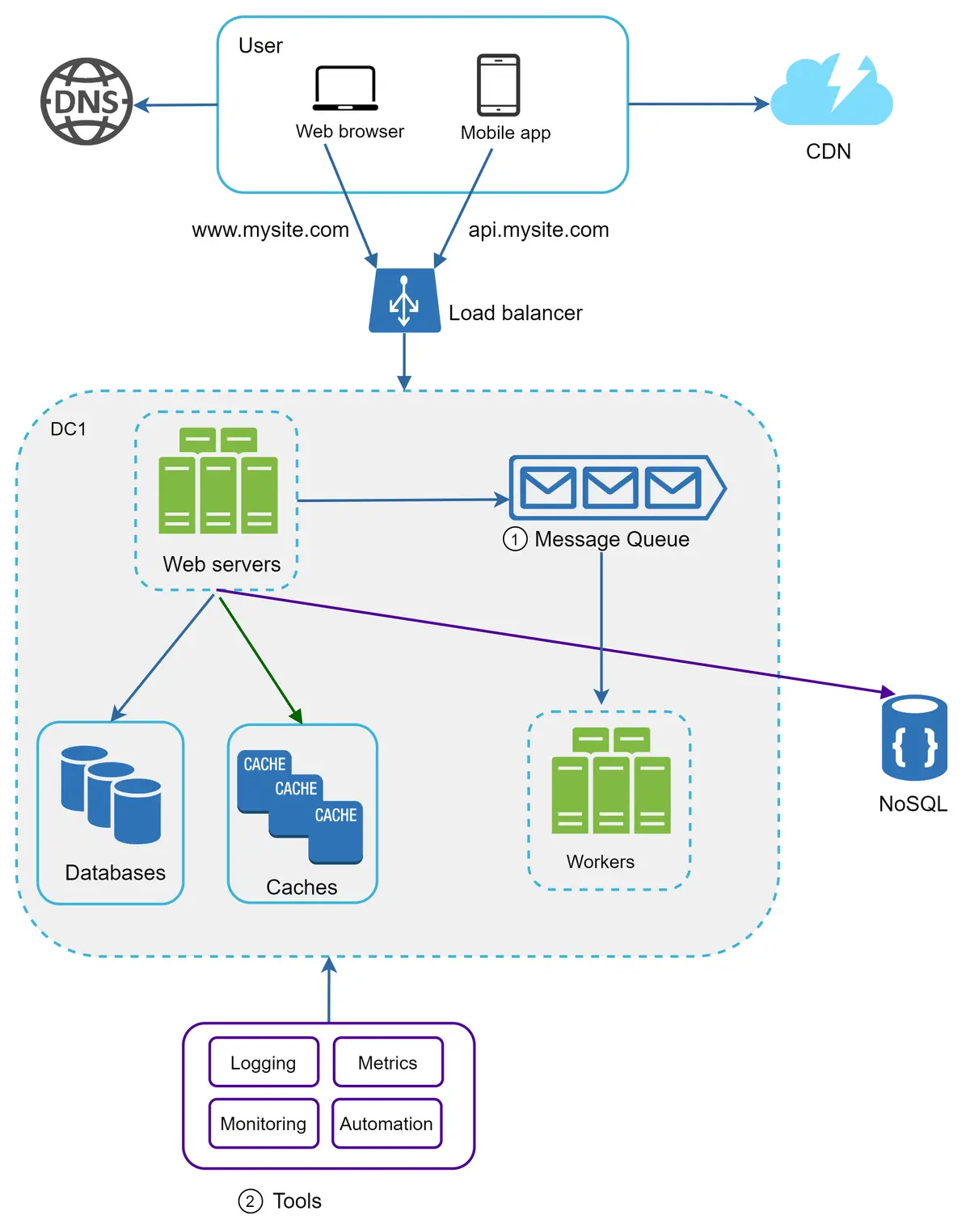
Gambar 19¶
Desain ini mencakup antrean pesan, yang membantu membuat sistem lebih longgar dan lebih tangguh terhadap kegagalan.
Alat pencatatan, pemantauan, metrik, dan otomatisasi disertakan.
Seiring bertambahnya data setiap hari, basis data Anda akan semakin kelebihan beban. Saatnya untuk meningkatkan skala lapisan data.
Database scaling¶
Ada dua pendekatan umum untuk penskalaan basis data: penskalaan vertikal dan penskalaan horizontal.
Penskalaan Vertikal¶
Penskalaan vertikal, juga dikenal sebagai peningkatan skala, adalah penskalaan dengan menambahkan lebih banyak daya (CPU, RAM, DISK, dll.) ke mesin yang sudah ada. Ada beberapa server basis data yang canggih. Menurut Amazon Relational Database Service (RDS) [12], Anda bisa mendapatkan server basis data dengan RAM 24 TB. Server basis data canggih seperti ini dapat menyimpan dan menangani banyak data. Misalnya, stackoverflow.com pada tahun 2013 memiliki lebih dari 10 juta pengunjung unik bulanan, tetapi hanya memiliki 1 basis data utama [13]. Namun, penskalaan vertikal memiliki beberapa kelemahan serius:
Anda dapat menambahkan lebih banyak CPU, RAM, dll. ke server basis data Anda, tetapi ada batasan perangkat keras. Jika Anda memiliki basis pengguna yang besar, satu server saja tidak cukup.
Risiko kegagalan tunggal lebih tinggi.
Biaya keseluruhan penskalaan vertikal tinggi. Server yang kuat jauh lebih mahal.
Penskalaan horizontal¶
Penskalaan horizontal, juga dikenal sebagai sharding, adalah praktik penambahan server. Gambar 20 membandingkan penskalaan vertikal dengan penskalaan horizontal.

Gambar 20¶
Sharding memisahkan basis data besar menjadi bagian-bagian yang lebih kecil dan lebih mudah dikelola yang disebut shard. Setiap shard berbagi skema yang sama, meskipun data aktual pada setiap shard bersifat unik untuk setiap shard.
Gambar 21 menunjukkan contoh basis data yang di-sharding. Data pengguna dialokasikan ke server basis data berdasarkan ID pengguna. Setiap kali Anda mengakses data, fungsi hash digunakan untuk menemukan shard yang sesuai. Dalam contoh kita, user_id %4 digunakan sebagai fungsi hash. Jika hasilnya sama dengan 0, shard 0 digunakan untuk menyimpan dan mengambil data. Jika hasilnya sama dengan 1, shard 1 digunakan. Logika yang sama berlaku untuk shard lainnya.

Gambar 21¶
Gambar 22 menunjukkan tabel pengguna dalam basis data yang dibagi-bagi.

Gambar 22¶
Faktor terpenting yang perlu dipertimbangkan saat menerapkan strategi sharding adalah pilihan kunci sharding. Kunci sharding (dikenal sebagai kunci partisi) terdiri dari satu atau beberapa kolom yang menentukan bagaimana data didistribusikan. Seperti yang ditunjukkan pada Gambar 22, "user_id" adalah kunci sharding. Kunci sharding memungkinkan Anda mengambil dan memodifikasi data secara efisien dengan merutekan kueri basis data ke basis data yang tepat. Saat memilih kunci sharding, salah satu kriteria terpenting adalah memilih kunci yang dapat mendistribusikan data secara merata.
Sharding adalah teknik yang hebat untuk menskalakan basis data, tetapi masih jauh dari solusi yang sempurna. Sharding menghadirkan kompleksitas dan tantangan baru bagi sistem:
Resharding data: Pemecahan ulang data diperlukan ketika 1) satu shard tidak dapat lagi menampung lebih banyak data karena pertumbuhan yang pesat. 2) Shard tertentu mungkin mengalami kelelahan shard lebih cepat daripada yang lain karena distribusi data yang tidak merata. Ketika kelelahan shard terjadi, diperlukan pembaruan fungsi sharding dan pemindahan data. Hashing yang konsisten adalah teknik yang umum digunakan untuk mengatasi masalah ini.
Celebrity problem: Ini juga disebut masalah kunci hotspot. Akses berlebihan ke shard tertentu dapat menyebabkan server kelebihan beban. Bayangkan data untuk Katy Perry, Justin Bieber, dan Lady Gaga semuanya berakhir di shard yang sama. Untuk aplikasi sosial, shard tersebut akan kewalahan dengan operasi baca. Untuk mengatasi masalah ini, kita mungkin perlu mengalokasikan shard untuk setiap selebritas. Setiap shard bahkan mungkin memerlukan partisi lebih lanjut.
Join and de-normalization: Setelah database dipecah di beberapa server, sulit untuk melakukan operasi penggabungan di seluruh shard database. Solusi umum adalah dengan mendenormalisasi basis data sehingga kueri dapat dilakukan dalam satu tabel.
Pada Gambar 23, kami melakukan sharding basis data untuk mendukung lalu lintas data yang meningkat pesat. Pada saat yang sama, beberapa fungsi non-relasional dipindahkan ke penyimpanan data NoSQL untuk mengurangi beban basis data. Berikut adalah artikel yang membahas berbagai kasus penggunaan NoSQL [14].
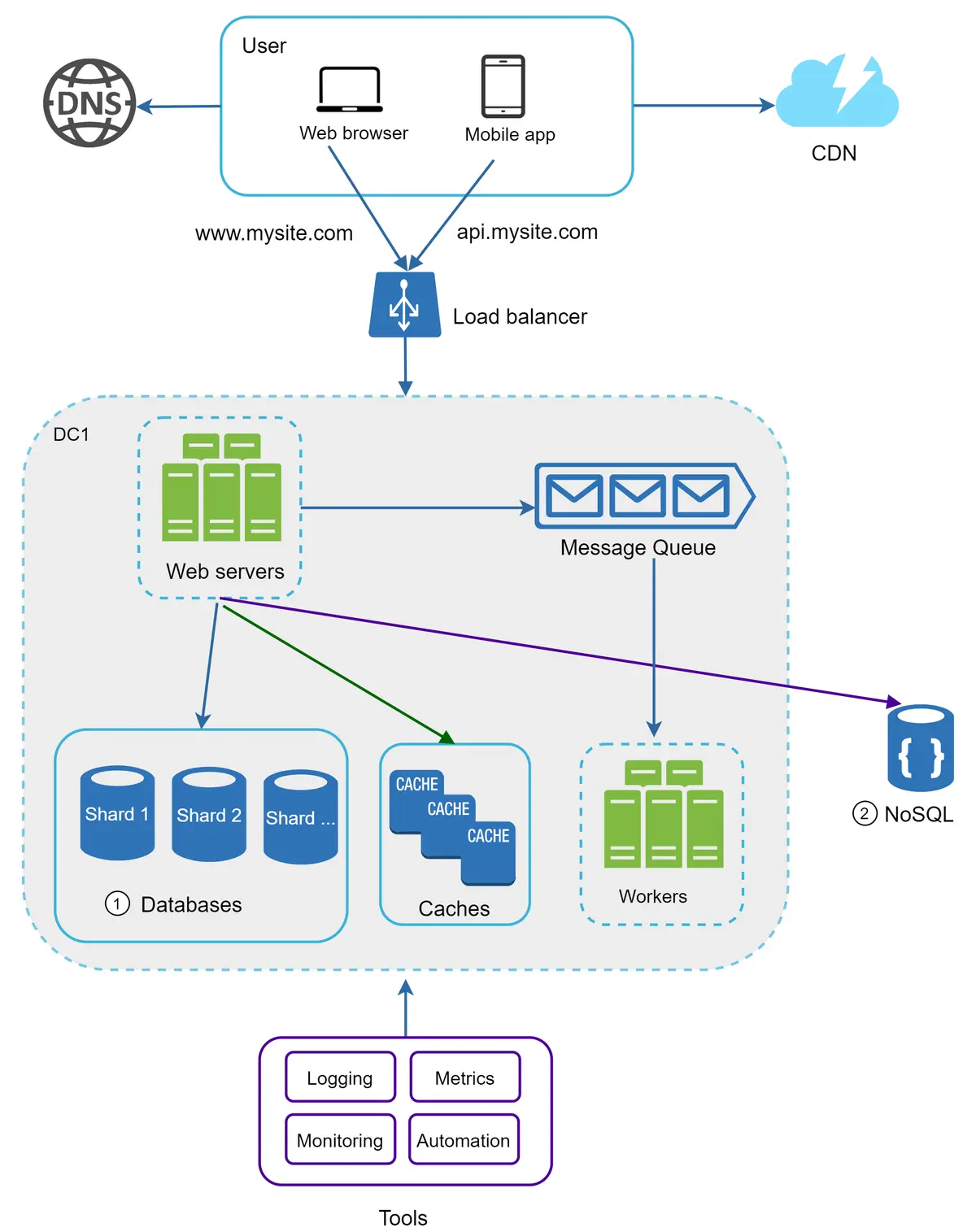
Gambar 23¶
Jutaan pengguna dan seterusnya¶
Menskalakan sistem adalah proses berulang. Mengulang apa yang telah kita pelajari di bab ini dapat membawa kita lebih jauh. Penyempurnaan lebih lanjut dan strategi baru diperlukan untuk menskalakan sistem melampaui jutaan pengguna. Misalnya, Anda mungkin perlu mengoptimalkan sistem dan memisahkannya ke layanan yang lebih kecil. Semua teknik yang dipelajari dalam bab ini akan memberikan fondasi yang baik untuk mengatasi tantangan baru. Sebagai penutup bab ini, kami memberikan ringkasan tentang bagaimana kami menskalakan sistem kami untuk mendukung jutaan pengguna:
Menjaga web tier tetap stateless
Membangun redundansi di setiap tier
Menyimpan data dalam cache sebanyak mungkin
Mendukung beberapa pusat data
Menghosting aset statis di CDN
Menskalakan tier data Anda dengan sharding
Membagi tier menjadi layanan individual
Memantau sistem Anda dan menggunakan alat otomatisasi
Selamat telah mencapai sejauh ini! Sekarang, beri diri Anda tepukan di punggung. Kerja bagus!
Referensi¶
[1] Hypertext Transfer Protocol: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
[2] Should you go Beyond Relational Databases?: https://blog.teamtreehouse.com/should-you-go-beyond-relational-databases
[3] Replication: https://en.wikipedia.org/wiki/Replication_(computing)
[4] Multi-master replication: https://en.wikipedia.org/wiki/Multi-master_replication
[5] NDB Cluster Replication: Bidirectional and Circular Replication: https://dev.mysql.com/doc/refman/8.4/en/mysql-cluster-replication-multi-source.html
[6] Caching Strategies and How to Choose the Right One: https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
[7] R. Nishtala etc. al., "Scaling Memcache at Facebook," 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’13): https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
[8] Single point of failure: https://en.wikipedia.org/wiki/Single_point_of_failure
[9] Amazon CloudFront Dynamic Content Delivery: https://aws.amazon.com/cloudfront/dynamic-content/
[10] Configure Sticky Sessions for Your Classic Load Balancer: https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html
[11] Active-Active for Multi-Regional Resiliency: https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b
[12] Amazon EC2 High Memory Instances: https://aws.amazon.com/ec2/instance-types/high-memory/
[13] What it takes to run Stack Overflow: http://nickcraver.com/blog/2013/11/22/what-it-takes-to-run-stack-overflow
[14] What The Heck Are You Actually Using NoSQL For: http://highscalability.com/blog/2010/12/6/what-the-heck-are-you-actually-using-nosql-for.html