Merancang Pembatas Kecepatan (Rate Limiter)¶
Dalam sistem jaringan, pembatas kecepatan digunakan untuk mengontrol laju lalu lintas yang dikirim oleh klien atau layanan. Dalam dunia HTTP, pembatas kecepatan membatasi jumlah permintaan klien yang diizinkan untuk dikirim selama periode tertentu. Jika jumlah permintaan API melebihi ambang batas yang ditentukan oleh pembatas kecepatan, semua panggilan berlebih akan diblokir. Berikut beberapa contoh:
Seorang pengguna tidak boleh menulis lebih dari 2 postingan per detik.
Anda dapat membuat maksimal 10 akun per hari dari alamat IP yang sama.
Anda dapat mengklaim hadiah tidak lebih dari 5 kali per minggu dari perangkat yang sama.
Dalam bab ini, Anda diminta untuk merancang pembatas kecepatan. Sebelum memulai perancangan, pertama-tama kita akan melihat manfaat menggunakan pembatas kecepatan API:
Cegah kekurangan sumber daya akibat serangan Denial of Service (DoS) [1]. Hampir semua API yang diterbitkan oleh perusahaan teknologi besar menerapkan beberapa bentuk pembatasan kecepatan. Misalnya, Twitter membatasi jumlah tweet hingga 300 per 3 jam [2]. API Google Docs memiliki batas default berikut: 300 per pengguna per 60 detik untuk permintaan baca [3]. Pembatas kecepatan mencegah serangan DoS, baik yang disengaja maupun tidak disengaja, dengan memblokir panggilan berlebih.
Kurangi biaya. Membatasi permintaan berlebih berarti mengurangi jumlah server dan mengalokasikan lebih banyak sumber daya ke API berprioritas tinggi. Pembatasan kecepatan sangat penting bagi perusahaan yang menggunakan API pihak ketiga berbayar. Misalnya, Anda akan dikenakan biaya per panggilan untuk API eksternal berikut: memeriksa kredit, melakukan pembayaran, mengambil rekam medis, dll. Membatasi jumlah panggilan sangat penting untuk mengurangi biaya.
Cegah server kelebihan beban. Untuk mengurangi beban server, pembatas kecepatan digunakan untuk menyaring permintaan berlebih yang disebabkan oleh bot atau perilaku buruk pengguna.
Langkah 1 - Pahami masalah dan tetapkan cakupan desain¶
Pembatasan laju dapat diimplementasikan menggunakan berbagai algoritma, masing-masing dengan kelebihan dan kekurangannya. Interaksi antara pewawancara dan kandidat membantu memperjelas jenis pembatas laju yang ingin kita bangun.
Kandidat |
Pewawancara |
|---|---|
Pembatas laju seperti apa yang akan kita rancang? Apakah pembatas laju sisi klien atau pembatas laju API sisi server? |
Pertanyaan bagus. Kita fokus pada pembatas laju API sisi server. |
Apakah pembatas laju membatasi permintaan API berdasarkan IP, ID pengguna, atau properti lainnya? |
Pembatas laju harus cukup fleksibel untuk mendukung berbagai rangkaian aturan pembatasan. |
Berapa skala sistemnya? Apakah sistem ini dirancang untuk perusahaan rintisan atau perusahaan besar dengan basis pengguna yang besar? |
Sistem harus mampu menangani sejumlah besar permintaan. |
Apakah sistem ini akan berfungsi dalam lingkungan terdistribusi? |
Ya. |
Apakah pembatas kecepatan merupakan layanan terpisah atau sebaiknya diimplementasikan dalam kode aplikasi? |
Itu keputusan desain di tangan Anda. |
Apakah kita perlu memberi tahu pengguna yang dibatasi? |
Ya. |
Persyaratan¶
Berikut ringkasan persyaratan untuk sistem ini:
Batasi permintaan yang berlebihan secara akurat.
Latensi rendah. Pembatas laju tidak boleh memperlambat waktu respons HTTP.
Gunakan memori seminimal mungkin.
Pembatas laju terdistribusi. Pembatas laju dapat digunakan bersama di beberapa server atau proses.
Penanganan pengecualian. Tampilkan pengecualian yang jelas kepada pengguna ketika permintaan mereka dibatasi.
Toleransi kesalahan yang tinggi. Jika terdapat masalah dengan pembatas laju (misalnya, server cache offline), hal tersebut tidak memengaruhi keseluruhan sistem.
Langkah 2 - Usulkan desain tingkat tinggi dan dapatkan persetujuan¶
Mari kita sederhanakan semuanya dan gunakan model klien dan server dasar untuk komunikasi.
Di mana menempatkan pembatas laju?¶
Secara intuitif, Anda dapat menerapkan pembatas laju di sisi klien atau server.
Implementasi sisi klien. Secara umum, klien adalah tempat yang tidak dapat diandalkan untuk menerapkan pembatasan laju karena permintaan klien dapat dengan mudah dipalsukan oleh aktor jahat. Selain itu, kita mungkin tidak memiliki kendali atas implementasi klien.
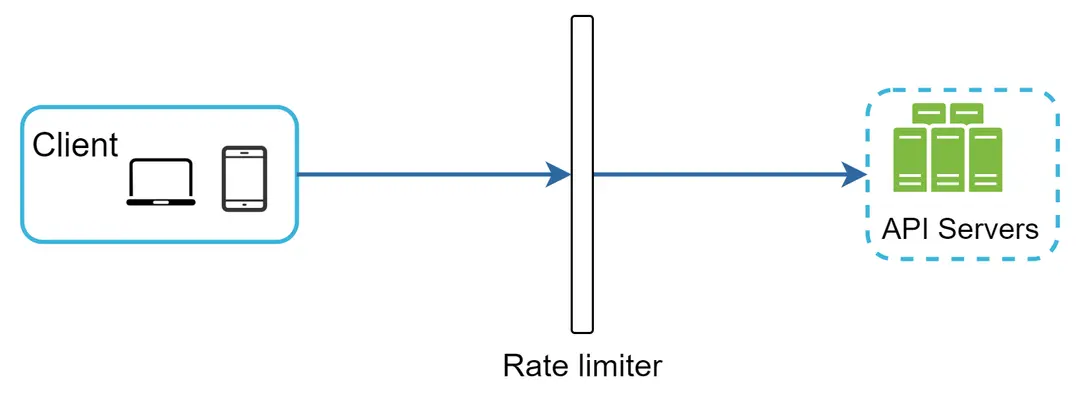
Implementasi sisi server. Gambar 1 menunjukkan pembatas laju yang ditempatkan di sisi server.

Selain implementasi sisi klien dan server, ada cara alternatif. Alih-alih menerapkan pembatas laju pada server API, kami membuat middleware pembatas laju yang membatasi permintaan ke API Anda seperti yang ditunjukkan pada Gambar 2.
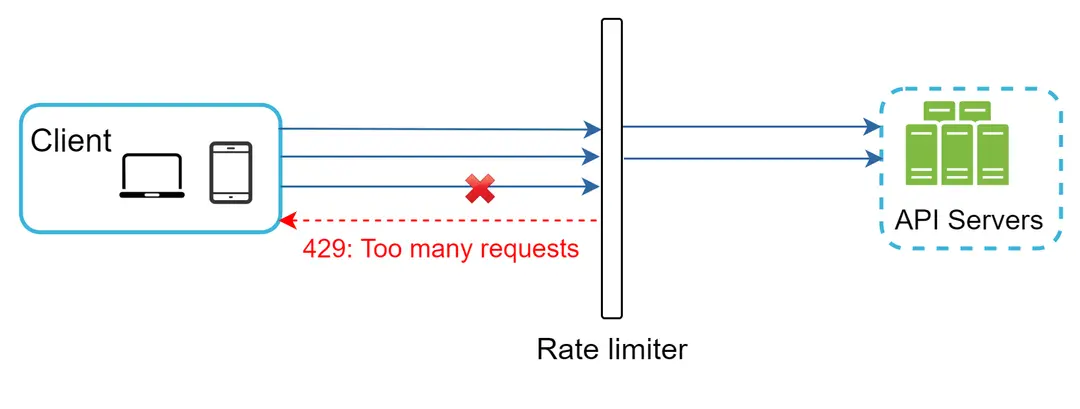
Mari kita gunakan contoh pada Gambar 3 untuk mengilustrasikan cara kerja pembatasan laju dalam desain ini. Asumsikan API kita mengizinkan 2 permintaan per detik, dan klien mengirimkan 3 permintaan ke server dalam satu detik. Dua permintaan pertama dirutekan ke server API. Namun, middleware pembatas laju membatasi permintaan ketiga dan mengembalikan kode status HTTP 429. Kode status respons HTTP 429 menunjukkan pengguna telah mengirimkan terlalu banyak permintaan.
Layanan mikro cloud [4] telah menjadi sangat populer dan pembatasan kecepatan biasanya diimplementasikan dalam komponen yang disebut API gateway. API gateway adalah layanan terkelola penuh yang mendukung pembatasan kecepatan, penghentian SSL, autentikasi, daftar putih IP, layanan konten statis, dll. Untuk saat ini, kita hanya perlu mengetahui bahwa API gateway adalah middleware yang mendukung pembatasan kecepatan.
Saat merancang pembatas kecepatan, pertanyaan penting yang perlu kita tanyakan pada diri sendiri adalah: di mana pembatas kecepatan harus diimplementasikan, di sisi server atau di gateway? Tidak ada jawaban mutlak. Hal ini bergantung pada tumpukan teknologi perusahaan Anda saat ini, sumber daya teknis, prioritas, tujuan, dll. Berikut adalah beberapa panduan umum:
Evaluasi tumpukan teknologi Anda saat ini, seperti bahasa pemrograman, layanan cache, dll. Pastikan bahasa pemrograman Anda saat ini efisien untuk menerapkan pembatasan laju di sisi server.
Identifikasi algoritma pembatasan laju yang sesuai dengan kebutuhan bisnis Anda. Ketika Anda mengimplementasikan semuanya di sisi server, Anda memiliki kendali penuh atas algoritma tersebut. Namun, pilihan Anda mungkin terbatas jika Anda menggunakan gateway pihak ketiga.
Jika Anda telah menggunakan arsitektur layanan mikro dan menyertakan gateway API dalam desain untuk melakukan autentikasi, daftar putih IP, dll., Anda dapat menambahkan pembatas laju ke gateway API.
Membangun layanan pembatasan laju Anda sendiri membutuhkan waktu. Jika Anda tidak memiliki cukup sumber daya teknis untuk mengimplementasikan pembatas laju, gateway API komersial adalah pilihan yang lebih baik.
Algoritma untuk pembatasan laju¶
Pembatasan laju dapat diimplementasikan menggunakan berbagai algoritma, dan masing-masing memiliki kelebihan dan kekurangannya masing-masing. Meskipun bab ini tidak berfokus pada algoritma, pemahaman mendalam tentang algoritma akan membantu kita memilih algoritma atau kombinasi algoritma yang tepat untuk kasus penggunaan kita. Berikut adalah daftar algoritma yang populer:
Token Bucket
Leaking Bucket
Fixed Window Counter
Sliding Window Log
Sliding Window Counter
Token bucket algorithm¶
Algoritma token bucket banyak digunakan untuk pembatasan laju. Algoritma ini sederhana, mudah dipahami, dan umum digunakan oleh perusahaan internet. Baik Amazon [5] maupun Stripe [6] menggunakan algoritma ini untuk membatasi permintaan API mereka.
Algoritma token bucket bekerja sebagai berikut:
Token bucket adalah wadah dengan kapasitas yang telah ditentukan sebelumnya. Token dimasukkan ke dalam bucket dengan laju yang telah ditentukan sebelumnya secara berkala. Setelah bucket penuh, tidak ada lagi token yang ditambahkan. Seperti yang ditunjukkan pada Gambar 4, kapasitas token bucket adalah 4. Pengisi ulang memasukkan 2 token ke dalam bucket setiap detik. Setelah bucket penuh, token tambahan akan meluap.

Setiap permintaan menggunakan satu token. Ketika permintaan tiba, kami memeriksa apakah ada cukup token di dalam bucket. Gambar 5 menjelaskan cara kerjanya.
Jika ada cukup token, kami mengambil satu token untuk setiap permintaan, dan permintaan tersebut diproses.
Jika tidak ada cukup token, permintaan akan dibatalkan.

Gambar 6 mengilustrasikan cara kerja logika konsumsi token, isi ulang, dan pembatasan laju. Dalam contoh ini, ukuran bucket token adalah 4, dan laju isi ulang adalah 4 per 1 menit.

Algoritme bucket token menggunakan dua parameter:
Ukuran bucket: jumlah maksimum token yang diizinkan dalam bucket
Tingkat pengisian ulang: jumlah token yang dimasukkan ke dalam bucket setiap detik
Berapa banyak bucket yang kita butuhkan? Hal ini bervariasi, dan bergantung pada aturan pembatasan laju. Berikut beberapa contoh.
Biasanya diperlukan bucket yang berbeda untuk titik akhir API yang berbeda. Misalnya, jika pengguna diizinkan membuat 1 postingan per detik, menambahkan 150 teman per hari, dan misalnya 5 postingan per detik, 3 bucket diperlukan untuk setiap pengguna.
Jika kita perlu membatasi permintaan berdasarkan alamat IP, setiap alamat IP memerlukan satu bucket.
Jika sistem mengizinkan maksimum 10.000 permintaan per detik, masuk akal untuk memiliki bucket global yang digunakan bersama oleh semua permintaan.
Kelebihan:
Algoritme ini mudah diimplementasikan.
Efisien memori.
Bucket token memungkinkan lonjakan lalu lintas dalam waktu singkat. Permintaan dapat diproses selama masih ada token yang tersisa.
Kekurangan:
Dua parameter dalam algoritma ini adalah ukuran bucket dan laju pengisian ulang token. Namun, mungkin sulit untuk menyetelnya dengan tepat.
Leaking bucket algorithm¶
Algoritma leaking bucket mirip dengan token bucket, hanya saja permintaan diproses dengan laju tetap. Algoritma ini biasanya diimplementasikan dengan antrean first-in-first-out (FIFO). Algoritma ini bekerja sebagai berikut:
Ketika permintaan masuk, sistem akan memeriksa apakah antrean sudah penuh. Jika belum penuh, permintaan akan ditambahkan ke antrean.
Jika tidak, permintaan akan dihapus.
Permintaan ditarik dari antrean dan diproses secara berkala.
Gambar 7 menjelaskan cara kerja algoritma ini.

Algoritma Leaky Bucket menggunakan dua parameter berikut:
Ukuran bucket: sama dengan ukuran antrean. Antrean menampung permintaan yang akan diproses pada kecepatan tetap.
Laju aliran keluar: menentukan berapa banyak permintaan yang dapat diproses pada kecepatan tetap, biasanya dalam hitungan detik.
Shopify, sebuah perusahaan e-commerce, menggunakan Leaky Bucket untuk pembatasan laju [7].
Kelebihan:
Hemat memori mengingat ukuran antrean yang terbatas.
Permintaan diproses pada kecepatan tetap, sehingga cocok untuk kasus penggunaan yang membutuhkan laju aliran keluar yang stabil.
Kekurangan:
Lonjakan lalu lintas memenuhi antrean dengan permintaan lama, dan jika tidak diproses tepat waktu, permintaan terbaru akan dibatasi lajunya.
Ada dua parameter dalam algoritma. Mungkin tidak mudah untuk menyetelnya dengan benar.
Fixed window counter algorithm¶
Algoritma penghitung jendela tetap bekerja sebagai berikut:
Algoritma membagi linimasa menjadi jendela waktu berukuran tetap dan menetapkan penghitung untuk setiap jendela.
Setiap permintaan akan menambah penghitung sebesar satu.
Setelah penghitung mencapai ambang batas yang telah ditentukan, permintaan baru akan dihentikan hingga jendela waktu baru dimulai.
Mari kita gunakan contoh konkret untuk melihat cara kerjanya. Pada Gambar 8, satuan waktu adalah 1 detik dan sistem mengizinkan maksimum 3 permintaan per detik. Pada setiap jendela kedua, jika lebih dari 3 permintaan diterima, permintaan tambahan akan dihentikan seperti yang ditunjukkan pada Gambar 8.

Masalah utama dengan algoritma ini adalah lonjakan lalu lintas di tepi jendela waktu dapat menyebabkan lebih banyak permintaan melewati batas kuota yang diizinkan. Perhatikan kasus berikut:

Pada Gambar 9, sistem mengizinkan maksimal 5 permintaan per menit, dan kuota yang tersedia akan direset pada menit putaran yang mudah diakses. Seperti yang terlihat, terdapat lima permintaan antara pukul 2:00:00 dan 2:01:00, dan lima permintaan lagi antara pukul 2:01:00 dan 2:02:00. Untuk jendela satu menit antara pukul 2:00:30 dan 2:01:30, 10 permintaan akan diproses. Jumlah tersebut dua kali lipat dari jumlah permintaan yang diizinkan.
Kelebihan:
Hemat memori.
Mudah dipahami.
Mereset kuota yang tersedia di akhir jendela waktu satuan cocok untuk kasus penggunaan tertentu.
Kekurangan:
Lonjakan lalu lintas di tepi jendela dapat menyebabkan lebih banyak permintaan yang diproses melebihi kuota yang diizinkan.
Sliding window log algorithm¶
Sebagaimana telah dibahas sebelumnya, algoritma penghitung jendela tetap memiliki masalah utama: algoritma ini memungkinkan lebih banyak permintaan melewati tepi jendela. Algoritma log jendela geser mengatasi masalah ini. Algoritma ini bekerja sebagai berikut:
Algoritma ini melacak stempel waktu permintaan. Data stempel waktu biasanya disimpan dalam cache, seperti kumpulan Redis yang diurutkan [8].
Ketika permintaan baru masuk, hapus semua stempel waktu yang kedaluwarsa. Stempel waktu kedaluwarsa didefinisikan sebagai stempel waktu yang lebih lama dari awal jendela waktu saat ini.
Tambahkan stempel waktu permintaan baru ke log.
Jika ukuran log sama atau lebih rendah dari hitungan yang diizinkan, permintaan akan diterima. Jika tidak, permintaan akan ditolak.
Kami menjelaskan algoritma ini dengan contoh seperti yang ditunjukkan pada Gambar 10.

Dalam contoh ini, pembatas laju mengizinkan 2 permintaan per menit. Biasanya, stempel waktu Linux disimpan dalam log. Namun, representasi waktu yang dapat dibaca manusia digunakan dalam contoh kami agar lebih mudah dibaca.
Log kosong ketika permintaan baru tiba pada pukul 1:00:01. Dengan demikian, permintaan tersebut diizinkan.
Permintaan baru tiba pada pukul 1:00:30, stempel waktu 1:00:30 dimasukkan ke dalam log. Setelah penyisipan, ukuran log adalah 2, tidak lebih besar dari jumlah yang diizinkan. Dengan demikian, permintaan tersebut diizinkan.
Permintaan baru tiba pada pukul 1:00:50, dan stempel waktu dimasukkan ke dalam log. Setelah penyisipan, ukuran log adalah 3, lebih besar dari ukuran yang diizinkan 2. Oleh karena itu, permintaan ini ditolak meskipun stempel waktu tetap ada di log.
Permintaan baru tiba pada pukul 1:01:40. Permintaan dalam rentang [1:00:40, 1:01:40] berada dalam rentang waktu terbaru, tetapi permintaan yang dikirim sebelum 1:00:40 dianggap kedaluwarsa. Dua stempel waktu yang kedaluwarsa, 1:00:01 dan 1:00:30, dihapus dari log. Setelah operasi penghapusan, ukuran log menjadi 2; oleh karena itu, permintaan diterima.
Kelebihan:
Pembatasan laju yang diterapkan oleh algoritma ini sangat akurat. Dalam setiap periode bergulir, permintaan tidak akan melebihi batas laju.
Kekurangan:
Algoritma ini menghabiskan banyak memori karena meskipun permintaan ditolak, stempel waktunya mungkin masih tersimpan di memori.
Sliding window counter algorithm¶
Algoritma penghitung jendela geser merupakan pendekatan hibrida yang menggabungkan penghitung jendela tetap dan log jendela geser. Algoritma ini dapat diimplementasikan dengan dua pendekatan berbeda. Kami akan menjelaskan salah satu implementasi di bagian ini dan memberikan referensi untuk implementasi lainnya di akhir bagian ini. Gambar 11 mengilustrasikan cara kerja algoritma ini.

Asumsikan pembatas laju mengizinkan maksimal 7 permintaan per menit, dan terdapat 5 permintaan pada menit sebelumnya dan 3 pada menit saat ini. Untuk permintaan baru yang tiba pada posisi 30% pada menit saat ini, jumlah permintaan dalam jendela bergulir dihitung menggunakan rumus berikut:
Permintaan di jendela saat ini + permintaan di jendela sebelumnya * persentase tumpang tindih jendela bergulir dan jendela sebelumnya
Dengan menggunakan rumus ini, kita mendapatkan 3 + 5 * 0,7% = 6,5 permintaan. Tergantung pada kasus penggunaannya, angka tersebut dapat dibulatkan ke atas atau ke bawah. Dalam contoh kita, angka tersebut dibulatkan ke bawah menjadi 6.
Karena pembatas laju mengizinkan maksimal 7 permintaan per menit, permintaan saat ini dapat diproses. Namun, batas tersebut akan tercapai setelah menerima satu permintaan lagi.
Karena keterbatasan ruang, kami tidak akan membahas implementasi lainnya di sini. Pembaca yang tertarik dapat merujuk ke materi referensi [9]. Algoritma ini tidak sempurna. Algoritma ini memiliki kelebihan dan kekurangan.
Kelebihan
Ini menghaluskan lonjakan lalu lintas karena rasionya didasarkan pada rasio rata-rata jendela sebelumnya.
Efisien memori.
Kekurangan
Ini hanya berfungsi untuk jendela lihat balik yang tidak terlalu ketat. Ini merupakan perkiraan rasio sebenarnya karena mengasumsikan permintaan di jendela sebelumnya terdistribusi secara merata. Namun, masalah ini mungkin tidak separah yang terlihat. Menurut eksperimen yang dilakukan oleh Cloudflare [10], hanya 0,003% permintaan yang salah diizinkan atau dibatasi rasionya di antara 400 juta permintaan.
High-level architecture¶
Ide dasar algoritma pembatasan laju sederhana. Pada tingkat tinggi, kita membutuhkan penghitung untuk melacak berapa banyak permintaan yang dikirim dari pengguna, alamat IP, dll. yang sama. Jika penghitung lebih besar dari batas, permintaan akan ditolak.
Di mana kita akan menyimpan penghitung? Menggunakan basis data bukanlah ide yang baik karena akses disk yang lambat. Cache dalam memori dipilih karena cepat dan mendukung strategi kedaluwarsa berbasis waktu. Misalnya, Redis [11] adalah opsi populer untuk mengimplementasikan pembatasan laju. Redis adalah penyimpanan dalam memori yang menawarkan dua perintah: INCR dan EXPIRE.
INCR: Meningkatkan penghitung yang disimpan sebesar 1.
EXPIRE: Menetapkan batas waktu untuk penghitung. Jika batas waktu berakhir, penghitung akan dihapus secara otomatis.
Gambar 12 menunjukkan arsitektur tingkat tinggi untuk pembatasan laju, dan cara kerjanya sebagai berikut:
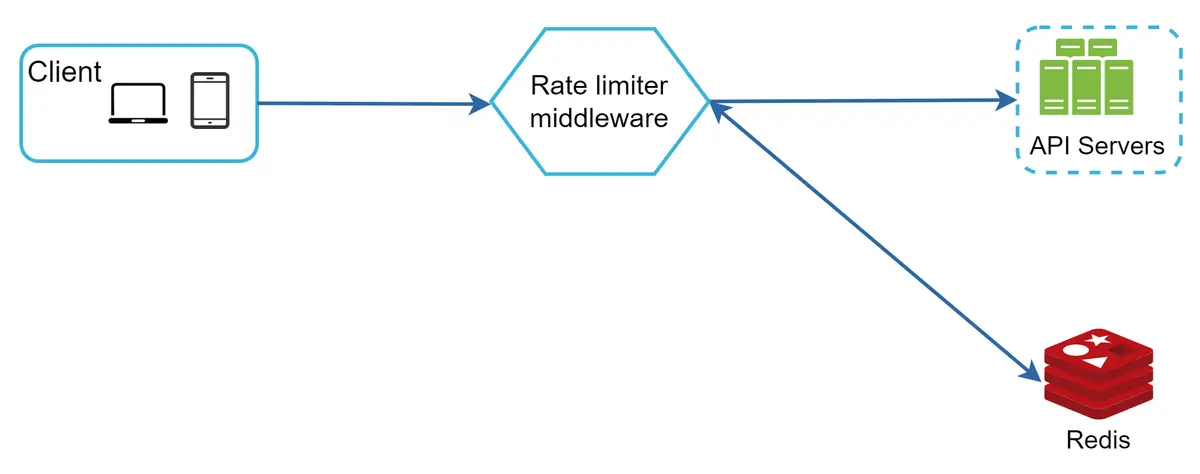
Klien mengirimkan permintaan ke middleware pembatas laju.
Middleware pembatas laju mengambil penghitung dari bucket terkait di Redis dan memeriksa apakah batas tercapai atau tidak.
Jika batas tercapai, permintaan ditolak.
Jika batas tidak tercapai, permintaan dikirim ke server API. Sementara itu, sistem menambah penghitung dan menyimpannya kembali ke Redis.
Langkah 3 - Analisis Desain Mendalam¶
Desain tingkat tinggi pada Gambar 12 tidak menjawab pertanyaan-pertanyaan berikut:
Bagaimana aturan pembatasan laju dibuat? Di mana aturan tersebut disimpan?
Bagaimana cara menangani permintaan yang dibatasi laju?
Di bagian ini, pertama-tama kita akan menjawab pertanyaan-pertanyaan terkait aturan pembatasan laju, kemudian membahas strategi untuk menangani permintaan yang dibatasi laju. Terakhir, kita akan membahas pembatasan laju dalam lingkungan terdistribusi, desain detail, optimasi kinerja, dan pemantauan.
Rate limiting rules¶
Lyft membuka sumber komponen pembatasan kecepatan mereka [12]. Kita akan mengintip ke dalam komponen dan melihat beberapa contoh aturan pembatasan kecepatan:
domain: pesan
descriptor:
- key: jenis_pesan
value: pemasaran
batas_kecepatan:
unit: hari
permintaan_per_unit: 5
Dalam contoh di atas, sistem dikonfigurasi untuk mengizinkan maksimal 5 pesan pemasaran per hari. Berikut contoh lainnya:
domain: autentikasi
descriptor:
- key: jenis_autentikasi
value: masuk
batas_kecepatan:
unit: menit
permintaan_per_unit: 5
Aturan ini menunjukkan bahwa klien tidak diizinkan untuk masuk lebih dari 5 kali dalam 1 menit. Aturan umumnya ditulis dalam berkas konfigurasi dan disimpan di disk.
Melebihi batas kecepatan¶
Jika permintaan dibatasi kecepatannya, API akan mengembalikan kode respons HTTP 429 (terlalu banyak permintaan) kepada klien. Tergantung pada kasus penggunaan, kami dapat mengantrekan permintaan yang dibatasi kecepatannya untuk diproses nanti. Misalnya, jika beberapa pesanan dibatasi kecepatannya karena kelebihan beban sistem, kami dapat menyimpan pesanan tersebut untuk diproses nanti.
Header pembatas laju¶
Bagaimana klien mengetahui apakah ia sedang dibatasi? Dan bagaimana klien mengetahui jumlah permintaan tersisa yang diizinkan sebelum dibatasi? Jawabannya terletak pada header respons HTTP. Pembatas laju mengembalikan header HTTP berikut kepada klien:
X-Ratelimit-Remaining: Jumlah permintaan tersisa yang diizinkan dalam rentang waktu tersebut.
X-Ratelimit-Limit: Menunjukkan berapa banyak panggilan yang dapat dilakukan klien per rentang waktu tersebut.
X-Ratelimit-Retry-After: Jumlah detik untuk menunggu hingga Anda dapat membuat permintaan lagi tanpa dibatasi.
Ketika pengguna mengirimkan terlalu banyak permintaan, kesalahan 429 permintaan terlalu banyak dan header X-Ratelimit-Retry-After akan dikembalikan ke klien.
Desain terperinci¶
Gambar 13 menyajikan desain sistem secara terperinci.
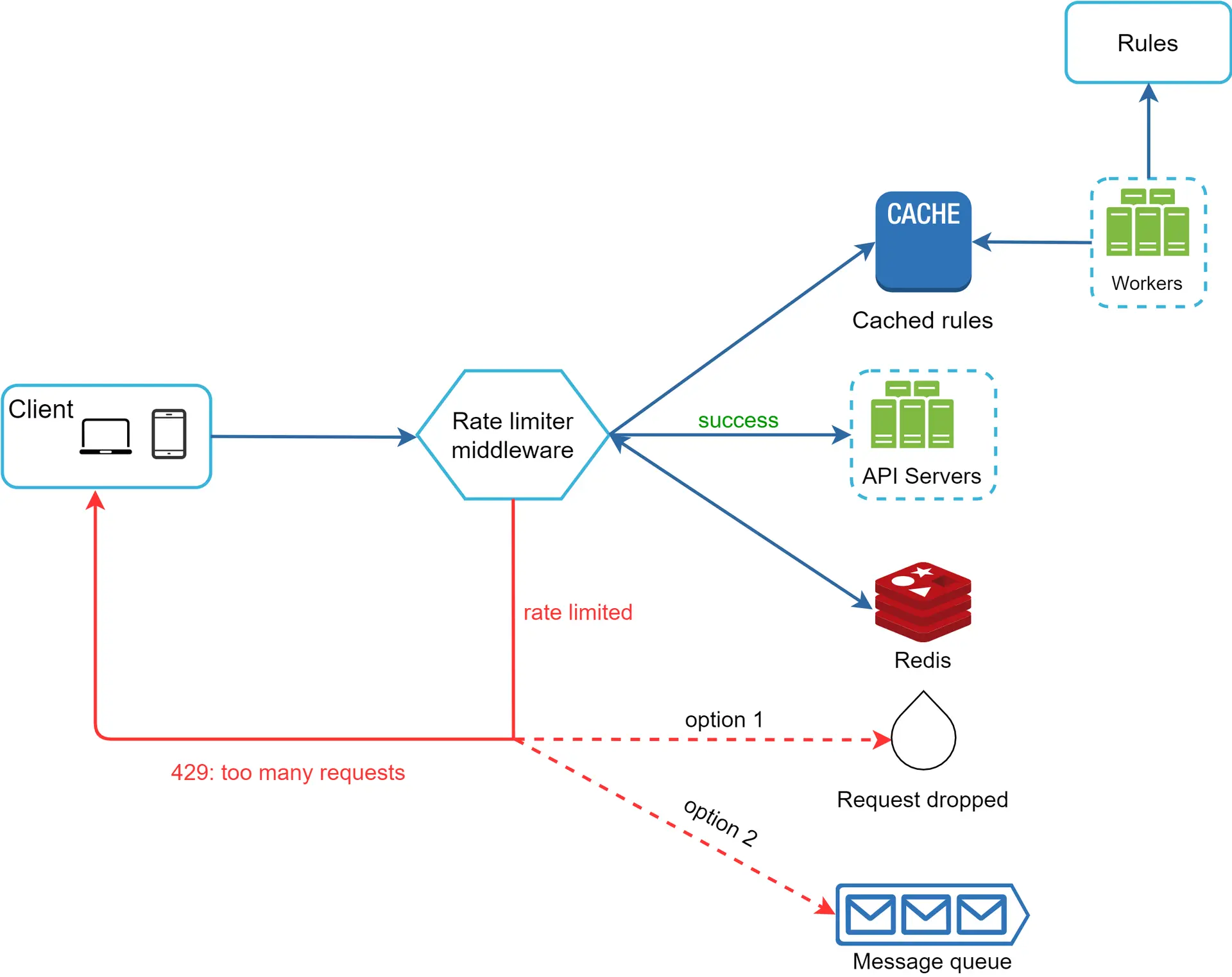
Aturan disimpan di disk. Pekerja sering kali mengambil aturan dari disk dan menyimpannya di cache.
Ketika klien mengirimkan permintaan ke server, permintaan tersebut akan dikirim terlebih dahulu ke middleware pembatas laju.
Middleware pembatas laju memuat aturan dari cache. Middleware ini mengambil penghitung dan stempel waktu permintaan terakhir dari cache Redis. Berdasarkan respons tersebut, pembatas laju memutuskan:
Jika permintaan tidak dibatasi laju, permintaan tersebut akan diteruskan ke server API.
Jika permintaan dibatasi laju, pembatas laju akan mengembalikan kesalahan 429 permintaan terlalu banyak kepada klien. Sementara itu, permintaan akan dibatalkan atau diteruskan ke antrean.
Pembatas laju dalam lingkungan terdistribusi¶
Membangun pembatas laju yang berfungsi dalam satu lingkungan server tidaklah sulit. Namun, menskalakan sistem untuk mendukung beberapa server dan thread konkuren adalah hal yang berbeda. Ada dua tantangan:
Race condition
Masalah sinkronisasi
Race condition¶
Seperti yang telah dibahas sebelumnya, pembatas laju bekerja sebagai berikut pada tingkat tinggi:
Baca nilai penghitung dari Redis.
Periksa apakah (penghitung + 1) melebihi ambang batas.
Jika tidak, tambahkan nilai penghitung sebesar 1 di Redis.
Kondisi balapan dapat terjadi dalam lingkungan yang sangat konkuren seperti yang ditunjukkan pada Gambar 14.

Asumsikan nilai penghitung di Redis adalah 3. Jika dua permintaan membaca nilai penghitung secara bersamaan sebelum salah satu dari mereka menulis kembali nilainya, masing-masing akan menambah penghitung sebanyak satu dan menulisnya kembali tanpa memeriksa utas lainnya. Kedua permintaan (utas) yakin bahwa mereka memiliki nilai penghitung yang benar, yaitu 4. Namun, nilai penghitung yang benar seharusnya adalah 5.
Penguncian adalah solusi paling jelas untuk mengatasi kondisi balapan. Namun, penguncian akan memperlambat sistem secara signifikan. Dua strategi umum digunakan untuk menyelesaikan masalah ini: skrip Lua [13] dan struktur data set terurut di Redis [8]. Bagi pembaca yang tertarik dengan strategi ini, silakan merujuk ke materi referensi terkait [8] [13].
Masalah sinkronisasi¶
Sinkronisasi merupakan faktor penting lainnya yang perlu dipertimbangkan dalam lingkungan terdistribusi. Untuk mendukung jutaan pengguna, satu server pembatas laju mungkin tidak cukup untuk menangani lalu lintas. Ketika beberapa server pembatas laju digunakan, sinkronisasi diperlukan. Misalnya, di sisi kiri Gambar 15, klien 1 mengirimkan permintaan ke pembatas laju 1, dan klien 2 mengirimkan permintaan ke pembatas laju 2. Karena tingkat web bersifat stateless, klien dapat mengirimkan permintaan ke pembatas laju yang berbeda seperti yang ditunjukkan di sisi kanan Gambar 15. Jika tidak terjadi sinkronisasi, pembatas laju 1 tidak berisi data apa pun tentang klien 2. Dengan demikian, pembatas laju tidak dapat berfungsi dengan baik.
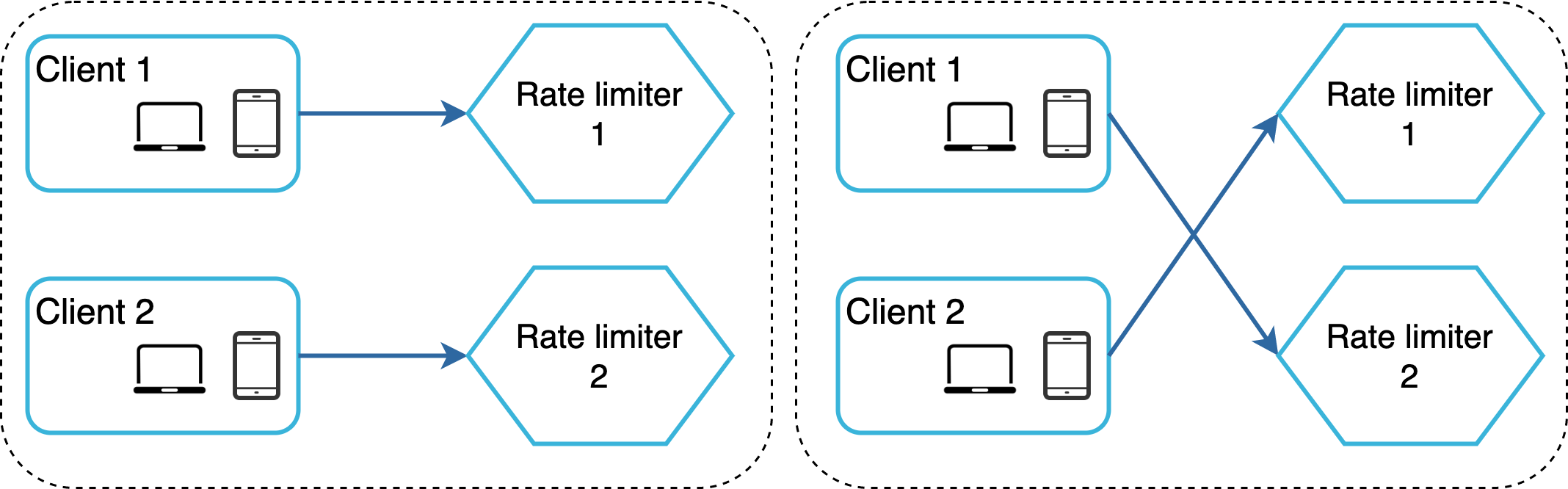
Salah satu solusi yang memungkinkan adalah menggunakan sesi lengket yang memungkinkan klien mengirimkan lalu lintas ke pembatas laju yang sama. Solusi ini tidak disarankan karena tidak skalabel maupun fleksibel. Pendekatan yang lebih baik adalah menggunakan penyimpanan data terpusat seperti Redis. Desainnya ditunjukkan pada Gambar 16.
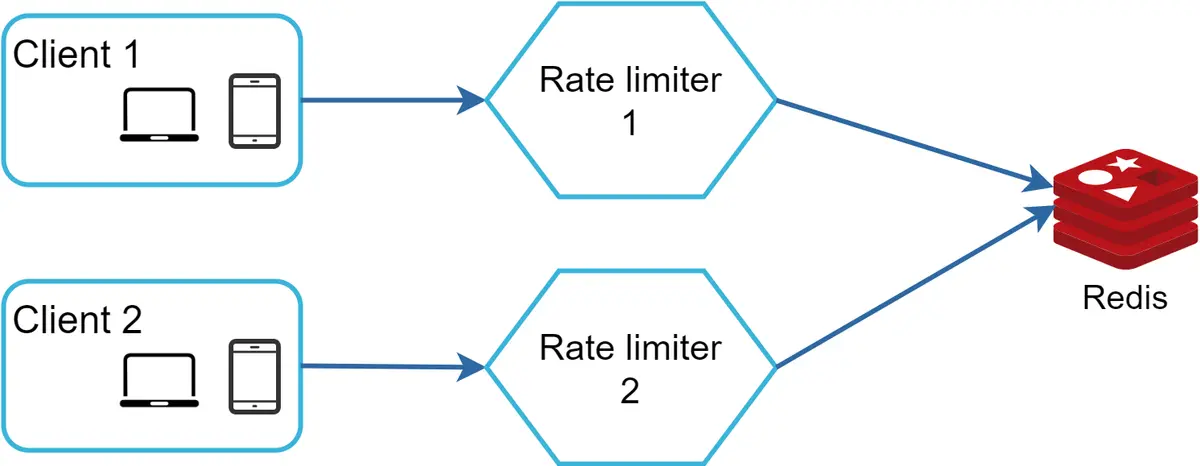
Optimasi kinerja¶
Optimalisasi kinerja merupakan topik umum dalam wawancara desain sistem. Kami akan membahas dua area yang perlu ditingkatkan.
Pertama, pengaturan multi-pusat data sangat penting untuk pembatas kecepatan karena latensi tinggi bagi pengguna yang berlokasi jauh dari pusat data. Sebagian besar penyedia layanan cloud membangun banyak lokasi server edge di seluruh dunia. Misalnya, per 20 Mei 2020, Cloudflare memiliki 194 server edge yang tersebar secara geografis [14]. Lalu lintas secara otomatis dialihkan ke server edge terdekat untuk mengurangi latensi.
Kedua, sinkronkan data dengan model konsistensi akhir. Jika Anda kurang jelas tentang model konsistensi akhir, lihat bagian "Konsistensi" di bab "Merancang Penyimpanan Nilai-Kunci".
Pemantauan (Monitoring)¶
Setelah pembatas laju diterapkan, penting untuk mengumpulkan data analitik guna memeriksa efektivitasnya. Pertama-tama, kami ingin memastikan:
Algoritma pembatas laju efektif.
Aturan pembatas laju efektif.
Misalnya, jika aturan pembatas laju terlalu ketat, banyak permintaan valid yang ditolak. Dalam hal ini, kami ingin sedikit melonggarkan aturan tersebut. Dalam contoh lain, kami melihat pembatas laju kami menjadi tidak efektif ketika terjadi peningkatan trafik secara tiba-tiba seperti penjualan kilat. Dalam skenario ini, kami dapat mengganti algoritma untuk mendukung trafik yang melonjak. Token bucket adalah solusi yang tepat.
Langkah 4 - Penutup¶
Dalam bab ini, kita membahas berbagai algoritma pembatasan laju dan pro/kontranya. Algoritma yang dibahas meliputi:
Bucket token
Bucket bocor
Jendela tetap
Log jendela geser
Penghitung jendela geser
Kemudian, kita membahas arsitektur sistem, pembatas laju dalam lingkungan terdistribusi, optimasi dan pemantauan kinerja. Layaknya pertanyaan wawancara desain sistem lainnya, ada poin-poin pembahasan tambahan yang dapat Anda sebutkan jika waktu memungkinkan:
Pembatasan laju keras vs lunak.
Keras: Jumlah permintaan tidak boleh melebihi ambang batas.
Lembut: Permintaan dapat melebihi ambang batas untuk waktu yang singkat.
Pembatasan laju di berbagai tingkatan. Dalam bab ini, kita hanya membahas pembatasan laju di tingkat aplikasi (HTTP: lapisan 7). Pembatasan laju dapat diterapkan di lapisan lain. Misalnya, Anda dapat menerapkan pembatasan laju berdasarkan alamat IP menggunakan Iptables [15] (IP: lapisan 3). Catatan: Model Interkoneksi Sistem Terbuka (OSI) memiliki 7 lapisan [16]: Lapisan 1: Lapisan fisik, Lapisan 2: Lapisan tautan data, Lapisan 3: Lapisan jaringan, Lapisan 4: Lapisan transport, Lapisan 5: Lapisan sesi, Lapisan 6: Lapisan presentasi, Lapisan 7: Lapisan aplikasi.
Hindari pembatasan laju. Rancang klien Anda dengan praktik terbaik:
Gunakan cache klien untuk menghindari panggilan API yang sering.
Pahami batasannya dan jangan mengirim terlalu banyak permintaan dalam waktu singkat.
Sertakan kode untuk menangkap pengecualian atau kesalahan agar klien Anda dapat pulih dari pengecualian dengan lancar.
Tambahkan waktu mundur yang cukup untuk mencoba ulang logika.
Selamat telah mencapai sejauh ini! Sekarang beri tepukan di punggung Anda. Kerja bagus!
Referensi¶
[1] Rate-limiting strategies and techniques: https://cloud.google.com/solutions/rate-limiting-strategies-techniques
[2] Twitter rate limits: https://developer.twitter.com/en/docs/basics/rate-limits
[3] Google docs usage limits: https://developers.google.com/docs/api/limits
[4] IBM microservices: https://www.ibm.com/cloud/learn/microservices
[5] Throttle API requests for better throughput: https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-request-throttling.html
[6] Stripe rate limiters: https://stripe.com/blog/rate-limiters
[7] Shopify REST Admin API rate limits: https://help.shopify.com/en/api/reference/rest-admin-api-rate-limits
[8] Better Rate Limiting With Redis Sorted Sets: https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/
[9] System Design — Rate limiter and Data modelling: https://medium.com/@saisandeepmopuri/system-design-rate-limiter-and-data-modelling-9304b0d18250
[10] How we built rate limiting capable of scaling to millions of domains: https://blog.cloudflare.com/counting-things-a-lot-of-different-things/
[11] Redis website: https://redis.io/
[12] Lyft rate limiting: https://github.com/lyft/ratelimit
[13] Scaling your API with rate limiters: https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d#request-rate-limiter
[14] What is edge computing: https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/
[15] Rate Limit Requests with Iptables: https://blog.programster.org/rate-limit-requests-with-iptables
[16] OSI model: https://en.wikipedia.org/wiki/OSI_model#Layer_architecture